
GPU·HBM의 발열·비용 문제를 넘어, 삼성의 온디바이스 AI 전략
지난 10년간 인공지능(AI) 혁신의 중심에는 GPU와 HBM이 있었습니다. 엔비디아는 고성능 GPU와 초고속 메모리를 결합해 대규모 AI 학습을 가능하게 하며 AI 황금기를 열었습니다. 그러나 시간이 지나면서 이 구조의 한계와 균열이 드러나고 있습니다. HBM은 가격이 비싸고 생산 난도가 높아 안정적인 공급망을 만들기 어렵고, GPU는 발열과 전력 소모로 인해 데이터센터 운영 비용을 급격히 높이고 있습니다.
이러한 제약 속에서 AI 산업은 새로운 해법을 찾아야 하는 기로에 서 있습니다. 바로 온디바이스 AI입니다. 이는 클라우드 데이터센터에 의존하지 않고, 스마트폰·PC·자동차·웨어러블 같은 단말기 자체에서 AI 연산을 수행하는 방식입니다. 실시간성, 개인정보 보호, 에너지 효율성 측면에서 강력한 장점을 가진 이 접근법은 AI 산업의 무게중심을 클라우드에서 엣지로 이동시키는 패러다임 전환으로 평가받고 있습니다.
삼성은 이러한 변화의 최전선에서 움직이고 있습니다. 엑시노스 SoC에 탑재된 NPU, 저전력 메모리(LPDDR5X·GDDR7), 3층 적층 이미지센서를 통해 기존 GPU·HBM 중심 구조의 한계를 보완하며, 글로벌 빅테크와 협력해 새로운 AI 플랫폼을 구축하고 있습니다. 이 블로그에서는 엔비디아 중심의 GPU 시대가 맞이한 한계와, 삼성이 추진하는 전략적 전환이 어떻게 차세대 AI 산업의 판도를 바꿀 수 있는지를 심층적으로 살펴보겠습니다.
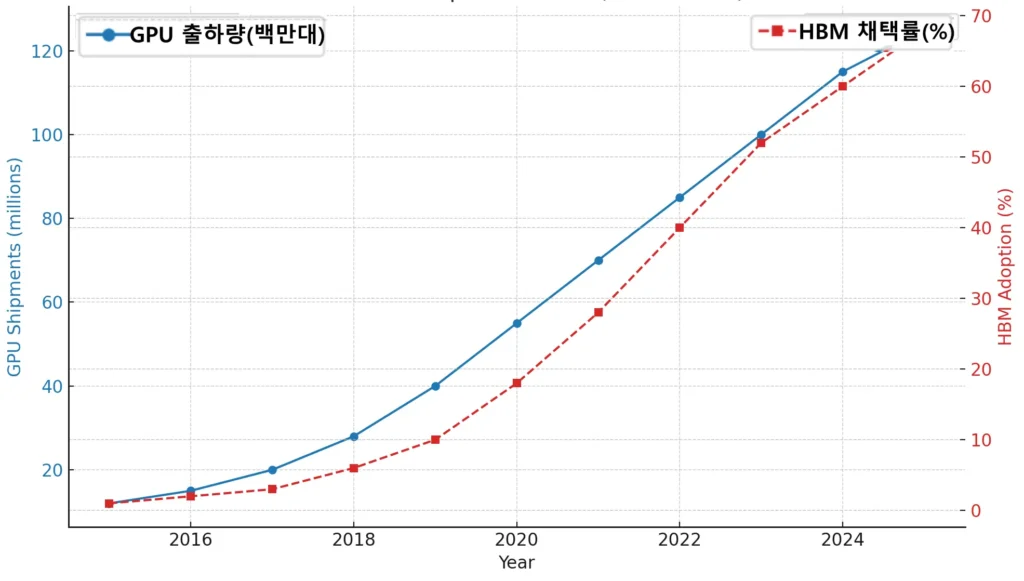
GPU 출하량 증가와 함께 HBM 채택률도 높아져, 비용과 발열 부담이 커지는 구조적 한계를 보여준다.
1. HBM 시대의 종언: AI 산업의 균열 신호
HBM 공급·가격의 구조적 한계
HBM(High Bandwidth Memory)은 기존 DRAM 대비 최대 5~10배의 대역폭을 제공하여 GPU 병목을 줄이는 핵심 기술입니다. 하지만 TSV(Through-Silicon Via) 적층 공정과 실리콘 인터포저 사용 때문에 제조 원가가 높습니다.
- HBM3E: 최대 9.2 Gbps 속도, 대역폭 1.2 TB/s 이상.
- 그러나 단가가 GB당 DDR5 대비 약 5배 이상 비싸며, 수율이 60~70% 수준에 머무르는 경우가 많습니다.
- 삼성·SK하이닉스·마이크론 등 소수 업체가 독점 공급해 공급망 리스크가 크고, 고객사(엔비디아·AMD)가 원하는 물량을 안정적으로 맞추기 어렵습니다.
데이터센터 비용 폭증과 전력·냉각 문제
GPU에 HBM을 탑재한 AI 서버는 고성능이지만, 전력 소비가 막대합니다.
- 엔비디아 H100 GPU TDP: 700W 이상, H200은 HBM3E 확장으로 더 높아질 전망.
- DGX H100 서버(8 GPUs) 전력 소모는 10kW 이상이며, 냉각 포함 TCO의 40% 이상이 전력/열 관리 비용에 해당합니다.
- 미국 데이터센터 전력 소비는 2024년 국가 전력의 4.4%에서 2030년에는 **10~12%**까지 늘어날 것으로 예상됩니다.
GPU 중심 구조의 지속 불가능성
GPU·HBM 조합은 성능 향상에는 기여하지만, 비용·발열·확장성이라는 삼중 병목을 초래합니다.
- 고도화된 AI 모델(예: GPT-5, Gemini)은 수천억~조 단위 파라미터를 요구하므로, GPU+HBM만으로는 효율적 확장이 불가능합니다.
- 이에 따라 업계는 새로운 연산 구조, 특히 온디바이스 추론 전용 NPU와 같은 대안을 찾기 시작했습니다.
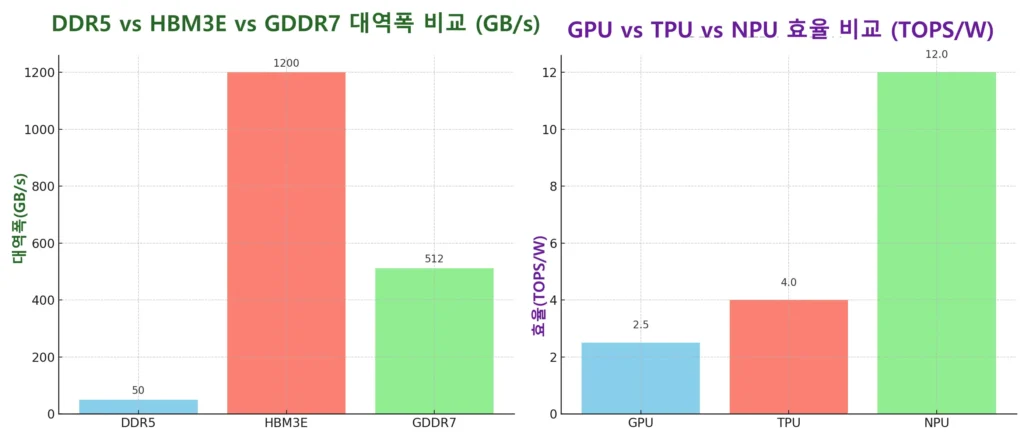
아래 두 개의 비교 그래프는 HBM 시대의 한계(메모리 비교)와 온디바이스 AI 부상(프로세서 비교)을 기술적으로 보여줍니다.
- 왼쪽: DDR5 vs HBM3E vs GDDR7 대역폭 비교 (GB/s)
→ HBM3E는 압도적인 대역폭을 제공하지만, 비용과 공정 복잡도가 큰 약점. - 오른쪽: GPU vs TPU vs NPU 효율 비교 (TOPS/W)
→ GPU는 고성능 학습에 강점, TPU는 클라우드 학습·추론에 최적화, NPU는 저전력 환경에서 압도적 효율을 보임.
👉 이 도표들은 GPU·HBM의 병목 구조와 NPU 기반 온디바이스 AI의 경쟁력을 직관적으로 보여 줍니다.
2. 온디바이스 AI의 부상: 새로운 패러다임 전환
온디바이스 AI란 무엇인가?
온디바이스 AI는 클라우드 대신 스마트폰, PC, 웨어러블, 자동차 같은 단말기 내부에서 AI 연산을 직접 수행하는 방식입니다.
- 장점: 지연(Latency) 최소화(100ms 이하 반응 가능), 개인정보 보호 강화, 네트워크 비용 절감.
- 단점: 학습(Training)에는 한계가 있어, 주로 추론(Inference) 중심으로 활용.
GPU, TPU, 그리고 NPU의 차이
- GPU: 수천 개의 코어로 병렬 연산을 수행, 학습(Training)에 강점. 단일 칩 TDP 수백 와트.
- TPU: 구글이 설계한 행렬연산 전용 ASIC, 클라우드 학습·추론 모두 지원. TPU v5p는 최대 1000+ TOPS 성능 제공.
- NPU: 초저전력 추론 전용 프로세서. INT8/INT4 같은 저정밀 연산을 활용해 1W당 수십 TOPS 효율을 제공.
- 애플 ANE: 35 TOPS (iPhone 15 Pro)
- 퀄컴 Hexagon NPU: 45 TOPS (Snapdragon X Elite)
- 삼성 Exynos 2500 NPU: 59 TOPS (2025 예정)
개인화·실시간·보안 중심으로 이동
온디바이스 AI는 단순한 효율 개선을 넘어, 사용자 경험(UX)의 패러다임 전환을 가능케 합니다.
- 개인화: 클라우드 전송 없이 개인 데이터를 기기에서 직접 처리. 예: 맞춤형 추천, 로컬 번역.
- 실시간성: 네트워크 지연 없이 즉각 반응. 예: AR/VR, 자율주행 보조.
- 보안성: 민감 데이터(음성, 얼굴, 건강 정보)를 외부 서버로 보내지 않아 데이터 유출 리스크 감소.
경제적으로도 효과가 큽니다. 기업이 클라우드 추론을 줄이고 온디바이스로 분산하면, 연간 수백만~수천만 달러의 클라우드 비용 절감이 가능합니다.
다음은 GPU·TPU·NPU의 핵심 차이점을 비교한 표입니다.
GPU vs TPU vs NPU 비교 표
| 특징 | GPU | TPU | NPU |
|---|---|---|---|
| 핵심 목적 | 범용 AI 가속 (학습 + 추론) | 구글 전용 AI 텐서 연산 | 온디바이스 AI 추론 |
| 강점 분야 | 대규모 LLM 학습, 방대한 AI 워크로드 | 구글 AI 서비스 (클라우드 규모) | 저전력, 실시간 추론 |
| 적용 위치 | 데이터센터, HPC | 구글 클라우드 전용 | 스마트폰, PC, 자동차, IoT |
| 전력 소모 | 매우 높음 (수백 와트 단위) | 높음, 하지만 대규모 연산에 최적화 | 매우 낮음 (밀리와트~와트 단위) |
| 예시 제품 | NVIDIA H100, AMD MI300X | 구글 TPU v4/v5 | 애플 ANE, 삼성 Exynos NPU, 퀄컴 Hexagon |
3. 삼성의 전략적 전환: 메모리·센서·프로세서 융합
엑시노스 SoC와 고성능 NPU
삼성의 엑시노스(Exynos) SoC는 CPU·GPU·DSP와 함께 전용 NPU를 통합해 온디바이스 AI를 구동할 수 있도록 설계되었습니다.
- 엑시노스 2400: RDNA3 기반 GPU(Xclipse 940)와 최대 17 TOPS 성능의 NPU 탑재.
- 엑시노스 2500(2025 예정): NPU 성능 59 TOPS, INT8·INT4 연산 지원으로 전력 효율 최적화.
- 특징: Mixed-Precision 방식을 활용해 모델을 퀀타이즈하여 실행, 연산량을 줄이면서도 정확도를 유지.
이 접근은 대규모 학습보다는 압축된 모델을 단말기에서 실시간 추론하는 데 집중하고 있습니다.
3층 적층 이미지센서와 엣지 비전 AI
삼성은 이미지센서에 3층 적층(Stacked) 구조를 적용해 픽셀, 아날로그, 디지털 층을 분리 설계했습니다.
- 픽셀 층: 이미지 캡처
- 아날로그 층: 신호 증폭과 노이즈 제거
- 디지털 층: AI 엔진 내장, 전처리 및 객체 인식 수행
이를 통해 카메라 단계에서부터 AI 기반 전처리가 가능하며, 자율주행이나 AR/VR처럼 지연이 허용되지 않는 환경에서 강력한 성능을 제공합니다.
저전력 메모리: LPDDR5X·GDDR7
삼성은 고비용·고발열 구조의 HBM을 보완하기 위해 저전력 메모리 기술을 강화하고 있습니다.
- LPDDR5X: 8533 Mbps 전송 속도, 초슬림 패키징(0.65mm)으로 모바일 기기에 최적화.
- GDDR7: 32 Gbps 속도, GDDR6 대비 전력 효율 20% 향상.
메모리 대역폭과 에너지 효율을 동시에 높임으로써, 엑시노스와 결합된 구조는 단말기에서 더욱 안정적이고 고도화된 AI 기능을 지원하게 됩니다.
4. 글로벌 협력 구도: MS·AMD·퀄컴과의 연대
마이크로소프트와의 전략적 협력
삼성은 마이크로소프트와 AI PC 및 Azure AI 생태계 중심으로 긴밀히 협력하고 있습니다.
- Copilot+ PC는 NPU 연산 성능 최소 40 TOPS 이상을 요구하며, 이는 온디바이스 AI가 단순 보조 기능이 아닌 운영 체제 수준의 필수 연산 블록으로 자리 잡았음을 보여줍니다.
- 예를 들어, 삼성과 퀄컴이 협력한 Galaxy Book4 Edge는 Snapdragon X Elite NPU(45 TOPS)를 활용해 Copilot+ 기능을 로컬에서 처리합니다. 이는 클라우드 서버 호출을 줄여 전력·비용을 절감하고, 마이크로소프트 Azure의 GPU 자원 사용 부담을 낮추는 구조로 이어집니다.
AMD와의 메모리·GPU 시너지
AMD는 엔비디아에 대한 GPU 대항마로, 삼성 메모리 기술과 결합해 차별화된 생태계를 구축하고 있습니다.
- Instinct MI300X GPU는 192GB HBM3 메모리를 탑재하며, 메모리 대역폭은 5.3 TB/s에 달합니다. 이때 삼성 HBM3E 공급은 AMD가 엔비디아 H100/H200 대비 비용 효율을 높이는 핵심 요인입니다.
- 경제적 관점에서, AMD MI300X는 엔비디아 H100 대비 약 20~30% 낮은 TCO를 제공할 수 있다는 분석이 있습니다. 이는 삼성 메모리 기술의 가격 경쟁력과 패키징 최적화 덕분입니다.
퀄컴과의 온디바이스 AI 동맹
모바일·AI PC 시장에서 퀄컴과 삼성의 협력은 전략적으로 중요합니다.
- 퀄컴 Snapdragon 8 Gen 3 NPU는 최대 45 TOPS를 제공하며, 이는 스마트폰에서 AI 기반 카메라·번역·게임 최적화를 가능하게 합니다.
- 삼성은 이를 뒷받침하는 **LPDDR5X(8533 Mbps)**와 차세대 **GDDR7(32 Gbps)**을 공급합니다.
- 이 조합은 AI PC와 웨어러블 기기까지 확장되어, 단말기 기반 AI가 클라우드 GPU 호출 대비 최대 70% 에너지 절감을 가능하게 합니다.
5. 온디바이스 AI의 실제 적용 사례
스마트폰: 사진·번역·개인 비서
- 삼성 갤럭시는 엑시노스 SoC의 NPU를 활용해 카메라에서 초당 수십억 번 연산을 처리하며, 야간 촬영 품질을 기존 대비 최대 2배 개선했습니다.
- 온디바이스 번역은 클라우드 호출을 줄여, 평균 지연 시간을 300ms 이하로 낮추고 데이터 요금 비용을 절감합니다.
- 개인 비서 기능(예: 음성 인식)은 매일 수억 건의 호출을 로컬에서 처리함으로써, 사용자 데이터가 외부 서버에 전송되지 않는 보안성 강화 효과를 제공합니다.
AI PC와 Copilot+ 경험
- Copilot+ PC는 이미지 생성, 문서 요약 같은 생성형 AI 기능을 로컬 NPU에서 처리합니다.
- 예시: Snapdragon X Elite 기반 삼성 AI PC는 45 TOPS 성능을 활용해 Stable Diffusion 모델을 2~3초 내 생성할 수 있습니다. 이는 동일 작업을 클라우드 GPU에 맡길 때보다 전력 소모를 50% 이상 절감합니다.
- 경제적 효과: 기업 차원에서 직원 1만 명이 AI PC를 활용할 경우, 연간 클라우드 사용료 절감액이 수천만 달러에 이를 수 있습니다.
자동차·웨어러블·IoT 확장
- 자동차: 온디바이스 AI는 카메라·라이다 데이터 처리를 실시간으로 수행하며, 이는 자율주행 시스템에서 평균 100ms 이하의 응답 속도를 보장합니다. 클라우드 방식 대비 안전성이 높습니다.
- 웨어러블: 스마트워치와 헬스케어 기기는 매초 수십만 개의 생체 데이터를 분석해 맞춤형 피드백을 제공하며, 배터리 사용량을 30% 절감하는 알고리즘 최적화가 적용됩니다.
- IoT: 스마트홈 기기들은 명령 처리 지연을 1초 미만으로 줄여, 사용자 경험 품질을 크게 개선합니다.
6. 경제적·산업적 파급효과
데이터센터 비용 구조의 변화
- 서버 하드웨어 중 메모리 비용은 전체 비용의 약 **40%**를 차지합니다(512 GB per socket, 1 TB 총 용량 기준)SemiAnalysis+2SemiAnalysis+2.
- 엔비디아 DGX H100 시스템의 경우 단일 서버 비용은 약 27만 달러에 달하며SemiAnalysis+1, GPU 기반 시스템의 전력 및 냉각 비용은 총 운영비의 상당 부분을 차지합니다.
- 미국 데이터센터의 전력 소비량은 전체 전력의 4.4%, 2028년에는 **6.7%~12%**까지 증가할 것으로 예상되며Semiconductor Engineering, 냉각에 드는 비용은 TCO에서 최대 **35%~45%**를 차지할 정도로 무시할 수 없습니다Wikipedia.
이처럼 온디바이스 AI의 확산은 단말기 내부 처리로 AI 연산을 분산시켜, 데이터센터 GPU 의존 구조의 높은 전력 비용과 TCO 부담을 완화하는 데 중요한 역할을 합니다.
반도체 공급망 및 산업구조 재편
- HBM 중심 구조는 극소수 기업에 의존하는 공급망을 형성해 가격과 수급 안정에 제약이 큽니다.
- 삼성은 메모리 및 로직 반도체 모두 공급할 수 있는 수직 통합(vertical integration) 구조를 갖추고 있어 이 영역에서 강력한 구조적 우위를 확보하고 있습니다.
엣지·온디바이스 AI 시장의 폭발적 성장
- 전 세계 온디바이스 AI 시장 규모는 2024년 약 86억 달러, 2030년에는 366억 달러로 성장할 것으로 예상되며, 연평균 성장률(CAGR)은 **27.8%**에 달합니다marketwatch.com+1grandviewresearch.com+1.
- 엣지 AI 전체 시장 규모 또한 2024년 207.8억 달러, 2030년 664.7억 달러, CAGR **21.7%**로 빠르게 확대될 전망입니다grandviewresearch.com.
- 더 세분화된 예측으로는 스마트 디바이스용 엣지 AI 시장이 2024년 275억 달러, 2034년 3850억 달러로 성장(CAGR 약 30.2%)할 것으로 분석됩니다market.us.
7. 엔비디아의 대응 전략과 한계
Grace CPU와 ARM 기반 전환 시도
엔비디아는 GPU 중심 구조의 한계를 완화하기 위해 Grace CPU Superchip을 출시했습니다.
- Grace는 ARM Neoverse 코어 72개를 탑재하고, LPDDR5X 메모리 대역폭 ~500 GB/s를 지원합니다.
- GPU와 Grace CPU를 NVLink로 연결해, HBM 의존도를 낮추고 메모리 병목을 줄이는 전략입니다.
- 그러나 CPU 기반 확장은 여전히 Inference 전력 효율 면에서 NPU보다 뒤처지며, 모바일·엣지 기기 경쟁에는 직접적으로 대응하지 못합니다.
CUDA 생태계 강화
엔비디아는 가장 강력한 자산인 CUDA 소프트웨어 생태계를 확장하고 있습니다.
- 전 세계 AI 프레임워크 중 80% 이상이 CUDA에 최적화되어 있으며, 이는 개발자 락인(lock-in)을 만들어 GPU 의존도를 높이는 결과를 낳습니다.
- 매년 CUDA 기반 개발자 수는 300만 명 이상 증가하고 있으며, 엔비디아는 이를 통해 플랫폼 종속성을 강화하려 하고 있습니다.
GPU 성능·메모리 확장 전략
- H200 GPU는 HBM3E 141GB 메모리와 4.8 TB/s 대역폭을 탑재해 H100 대비 1.8배 성능 향상을 제공합니다.
- Blackwell(2025 예정) 아키텍처는 FP4 연산을 지원해 효율을 2배 이상 개선할 예정입니다.
- 그러나 이 성능 증가는 곧바로 비용 상승으로 이어지며, 데이터센터 운영비 절감 효과는 제한적입니다. 예컨대 H200 서버 한 대 가격은 30만 달러를 상회할 것으로 추정됩니다.
온디바이스 AI로의 대응 한계
엔비디아는 Jetson, Orin과 같은 엣지 모듈을 제공하지만, 스마트폰·PC·웨어러블용 NPU 시장에서는 사실상 경쟁력이 없습니다.
- 애플(ANE, 18 TOPS 이상), 퀄컴(Snapdragon X Elite, 45 TOPS), 삼성(Exynos 2500, 59 TOPS) 등이 이미 시장을 선점하고 있으며, 엔비디아는 이 영역에서 뚜렷한 제품군을 내놓지 못했습니다.
- 결과적으로 엔비디아는 여전히 데이터센터 중심 모델에 갇혀 있으며, 비용·발열·공급망 문제를 근본적으로 해소하지 못한 상태입니다.
8. 차세대 AI 판도의 승자는 누구인가?
삼성 vs 애플 vs 퀄컴: 모바일 AI 전쟁
모바일 기기는 온디바이스 AI 확산의 최전선입니다.
- 삼성: Exynos 2500은 최대 59 TOPS의 NPU 성능을 제공하며, LPDDR5X·GDDR7 메모리와 결합해 전력 대비 성능 효율을 높이고 있습니다.
- 애플: A17 Pro와 M3 칩에 탑재된 Apple Neural Engine은 35 TOPS급 성능을 제공하며, macOS·iOS 생태계와 긴밀히 통합되어 있습니다.
- 퀄컴: Snapdragon X Elite는 NPU 45 TOPS 성능을 제공하며, Copilot+ PC 표준을 사실상 주도하고 있습니다.
경제적으로 보면, 모바일·PC용 NPU 시장은 2030년까지 연평균 **30% 이상 성장(CAGR)**이 예상되며, 이 경쟁 구도에서 삼성은 수직 통합 강점을 기반으로 애플·퀄컴과 대등한 싸움을 벌이고 있습니다.
인텔·AMD vs 엔비디아: AI PC와 서버 경쟁
- 인텔: Core Ultra(Lunar Lake)부터 NPU를 내장해, 2025년에는 연간 1억 개 이상의 AI PC 출하를 목표로 하고 있습니다.
- AMD: Ryzen AI 300 시리즈는 50 TOPS 수준의 NPU를 탑재, AI PC 성능에서 인텔을 압박하고 있습니다.
- 엔비디아: 여전히 GPU 시장 점유율 80% 이상을 유지하고 있지만, AI PC 표준에서 뚜렷한 입지를 확보하지 못한 상태입니다.
경제적 효과로 볼 때, AI PC 시장 규모는 2028년 150억 달러에 달할 것으로 전망되며, 엔비디아가 이 영역에서 뒤처질 경우 데이터센터 의존도가 더 심화될 수밖에 없습니다.
글로벌 패권 경쟁의 새로운 흐름
AI 패권은 이제 데이터센터만이 아니라, 모바일·PC·자동차·웨어러블까지 확장되는 복합 구조로 진화하고 있습니다.
- 데이터센터: 엔비디아가 여전히 강자
- AI PC: 인텔·AMD가 새로운 주도권 확보
- 모바일·웨어러블: 삼성·애플·퀄컴의 3파전
- 자동차: 테슬라, Mobileye, 삼성·퀄컴의 진입 가속
결국 차세대 AI 판도의 승자는 단일 기업이 아닌, 에코시스템을 얼마나 넓고 깊게 확보하느냐에 달려 있습니다. 삼성은 메모리·로직·디바이스까지 연결된 공급망과 글로벌 협력 네트워크를 무기로, 엣지 AI 전환의 핵심 축으로 부상할 가능성이 높습니다.
9. 결론: 엔비디아 이후, 온디바이스 AI가 여는 제2막
GPU와 HBM이 주도한 AI 산업은 놀라운 성과를 거두었지만, 비용·발열·공급망 제약이라는 구조적 한계에 직면했습니다. 이제 AI의 무게중심은 데이터센터에서 벗어나, 온디바이스 AI를 중심으로 새롭게 이동하고 있습니다.
삼성은 엑시노스 NPU, 3층 적층 이미지센서, LPDDR5X·GDDR7 메모리 기술을 통해 이러한 전환의 핵심 플레이어로 자리매김하고 있습니다. 마이크로소프트, AMD, 퀄컴과의 글로벌 협력은 클라우드-엣지 통합 생태계를 형성하며, AI PC·스마트폰·자동차·웨어러블 등 다양한 기기에서 실질적인 혁신을 만들어내고 있습니다.
경제적 전망은 투자자들에게 매우 의미 있습니다.
- 온디바이스 AI 시장: 2024년 86억 달러 → 2030년 366억 달러 (CAGR 27.8%).
- 엣지 AI 전체 시장: 2024년 207억 달러 → 2030년 665억 달러 (CAGR 21.7%).
- AI PC 시장: 2028년 약 150억 달러 규모 도달 예상.
이러한 수치는 반도체, 메모리, NPU, 이미지센서 생태계에 걸쳐 새로운 ROI 기회를 제공합니다. 특히, 데이터센터 의존 비용이 높은 엔비디아 중심 모델 대비, 온디바이스 AI 기반 모델은 전력 및 운영비 절감 효과가 크기 때문에 기업과 소비자 모두에게 경제적 매력이 큽니다.
투자자 입장에서 삼성은 메모리·로직·완제품을 아우르는 수직 통합 구조를 바탕으로, 시장 점유율을 다각도로 확대할 수 있는 잠재력을 보유합니다. 단순한 부품 공급업체가 아니라, 에코시스템 전체를 주도할 수 있는 기업이라는 점이 장기적 투자 매력으로 작용할 것입니다.
앞으로의 AI 경쟁은 단순한 연산 성능이 아니라, 생태계와 시장 확장성이 승부를 가르게 될 것입니다. 엔비디아 이후의 시대, 온디바이스 AI는 AI 산업의 제2막을 열어가며, 삼성은 투자자와 산업 모두에게 새로운 성장의 기회를 제공할 가능성이 가장 큰 주체로 부상하고 있습니다.
Meta Keywords: GPU 한계, GPU limitations, HBM 발열 문제, HBM overheating issue, HBM 비용, HBM cost, 온디바이스 AI, On-device AI, 삼성 AI 전략, Samsung AI strategy, NPU 시장, NPU market, 엣지 컴퓨팅, Edge computing, 데이터센터 전력 소비, Data center power consumption, AI PC, AI PC, 반도체 공급망, Semiconductor supply chain, 엑시노스 NPU, Exynos NPU, 저전력 메모리, Low-power memory, AI 반도체 전환, AI semiconductor transition





