
DeepSeek V3.1: The 685B-Parameter Open-Source Model Challenging GPT-5 and Claude at a Fraction of the Cost
On August 19, 2025, DeepSeek launched its V3.1 model, a major milestone in the open-source AI movement. Unlike the high-profile rollouts of OpenAI or Anthropic, this release came quietly through developer channels, yet delivered big: stronger programming ability, longer context handling, and technical upgrades that push the limits of open models.
The timing is crucial. In 2025, the AI race has been led by OpenAI’s GPT-5 and Anthropic’s Claude Opus—powerful but costly and restricted. DeepSeek V3.1 offers a different path: a 685-billion-parameter model, freely accessible and competitive in performance while dramatically cheaper.
Its disruption comes not only from scale but from economics. Producing coding results at about $1 per task versus nearly $70 for closed rivals, it challenges the belief that frontier AI must carry a premium price. This blend of power, coherence, and affordability makes V3.1 a turning point in how advanced AI is built and shared.
In the sections ahead, we’ll examine how this release reshapes competition, the innovations behind its design, and why businesses, researchers, and developers see it as a serious alternative to the most expensive proprietary models.
1. The Evolution of DeepSeek Models
Early Beginnings with V1
The DeepSeek project began as a small but ambitious effort to challenge the dominance of closed AI systems. With the release of V1, the team proved that a community-driven approach could deliver a working large language model. While it was not competitive with frontier systems, it demonstrated efficiency and openness, setting the stage for what was to come.
Building Momentum with V2
The next version, V2, introduced improvements in multilingual support, programming assistance, and reasoning. This release attracted attention from researchers and developers because it showed that the project was moving quickly and learning from each iteration. Although still behind leaders like GPT-4, V2 marked a critical step forward in establishing credibility.
The Breakthrough of V3
DeepSeek V3 represented a turning point, introducing innovations such as Mixture-of-Experts and Multi-Head Latent Attention. These architectural changes made it possible to scale to much larger parameter counts without losing efficiency. For the first time, an open-source model began to stand alongside commercial systems, proving that frontier-scale AI was no longer the sole domain of big corporations.
The Arrival of V3.1
With V3.1, DeepSeek delivered a 685-billion-parameter model that extended context length, improved programming ability, and enhanced coherence. It wasn’t just about being bigger—it was about being smarter and more accessible, designed to serve practical use cases while keeping costs dramatically lower than proprietary systems.
2. Inside DeepSeek V3.1’s Architecture
Mixture-of-Experts (MoE)
One of the central innovations is MoE, which activates only a small subset of experts for each task instead of using all parameters at once. This allows the model to scale while avoiding unnecessary computation, creating a balance between massive size and manageable efficiency.
Multi-Head Latent Attention (MLA)
MLA was introduced to handle long-context interactions more effectively. Traditional attention mechanisms slow down or lose accuracy as input length grows, but MLA distributes and compresses attention so the model can maintain coherence across thousands of tokens. This makes it well-suited for extended conversations or detailed technical tasks.
Precision Optimization
To further enhance efficiency, the model relies on a mix of floating-point precision formats. By using FP8 alongside traditional FP16 or FP32 where necessary, the system reduces memory demand and speeds up computation. The result is a model that remains reliable yet faster, especially in deployment environments with limited hardware.
Training Philosophy
Rather than pushing scale at any cost, the design philosophy behind V3.1 was to maximize real-world utility. Architectural choices were guided by practical deployment concerns, ensuring that the model could perform competitively without requiring billions of dollars in compute.
3. Benchmark Results: How DeepSeek V3.1 Performs
Coding Benchmark Performance
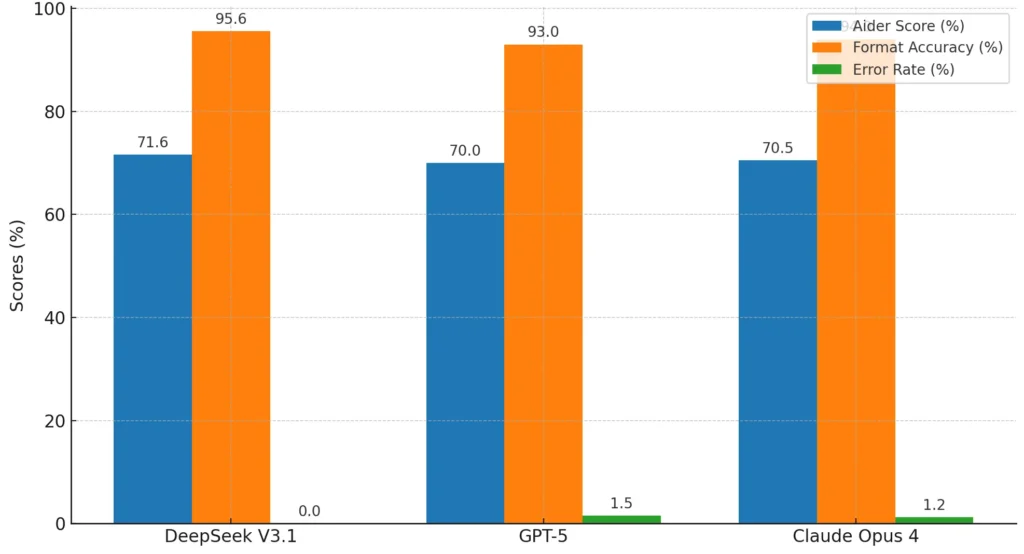
DeepSeek V3.1 was evaluated on the Aider coding benchmark, a respected measure of programming assistance. It achieved a 71.6% second-pass rate, placing it on par with some of the strongest proprietary models like Claude Opus 4. This performance signals that open-source systems can now compete head-to-head with premium solutions. The comparison becomes clearer when viewed in a side-by-side chart that highlights coding accuracy, format reliability, and error rates across models.
Format Accuracy and Error Reduction
Beyond the pass rate, the model showed exceptional reliability in output quality. Its format accuracy reached 95.6%, and it registered virtually no syntax or indentation errors. This means code generated by the model is not only correct but also ready to be implemented with minimal human correction, an essential factor for developer productivity.
Beyond Coding: Broader Capabilities
While coding tasks dominate the headlines, early evaluations suggest that DeepSeek V3.1 also excels in reasoning and conversation. Thanks to innovations like Multi-Head Latent Attention, it can sustain coherence across long documents or discussions, a feature that improves usability in education, research, and business contexts.
4. Cost Advantage: $1 vs. $70 per Task
Breaking the Cost Barrier
Perhaps the most disruptive aspect of DeepSeek V3.1 is its pricing efficiency. Each coding task costs just over $1, compared to nearly $70 for similar tasks when processed by proprietary systems. This cost advantage fundamentally reshapes the economics of AI adoption.
Why Enterprises Care
For organizations handling thousands of queries daily, the difference is more than incremental—it’s transformative. Lower costs reduce barriers for startups and allow enterprises to integrate AI into more workflows without worrying about runaway expenses. The model’s affordability provides a clear return on investment that proprietary rivals struggle to match.
Compounding Savings Across Workflows
The financial benefits extend beyond one-off coding tasks. When deployed in automated testing, debugging pipelines, or enterprise knowledge systems, cost reductions multiply. Over time, organizations that adopt DeepSeek V3.1 can reinvest savings into innovation, scaling, or infrastructure, creating long-term strategic value.
5. Comparing DeepSeek V3.1 with GPT-5 and Claude
Parameter Scale vs. Optimization
DeepSeek V3.1 carries 685 billion parameters, outpacing GPT-5 and Claude in sheer size. However, parameter count is not the only measure of intelligence. Proprietary models often leverage highly optimized training data and post-processing, allowing them to deliver more polished reasoning despite being smaller.
Long-Context Handling
One of the standout strengths of DeepSeek V3.1 is its ability to manage extended inputs. Thanks to Multi-Head Latent Attention, the model maintains coherence across long conversations and technical documents. GPT-5 shows similar strength, while Claude has been observed to be less consistent in handling extended contexts.
Cost and Accessibility
The most decisive factor is affordability. GPT-5 and Claude remain premium, closed ecosystems, accessible only through costly licensing. DeepSeek V3.1, by contrast, offers similar coding performance at a fraction of the cost, opening doors for developers, researchers, and enterprises that previously faced financial barriers.
Trade-Offs in Reliability
Where closed models still lead is refined reliability. Proprietary teams can fine-tune and monitor their models to minimize errors in high-stakes situations. DeepSeek V3.1, while powerful, places more responsibility on users to manage stability and safety, creating a balance between openness and dependability.
6. Open-Source vs. Proprietary AI: The Strategic Divide
Philosophical Differences
The arrival of DeepSeek V3.1 highlights a deeper divide in the AI industry. Proprietary models are designed for control, monetization, and brand-driven trust. Open-source alternatives emphasize accessibility, customization, and community-driven progress.
Advantages of Closed Systems
Closed ecosystems offer strong quality assurance. Enterprises benefit from customer support, regulated updates, and reliable safeguards against misuse. For industries that operate under strict compliance, this assurance can outweigh the costs.
The Promise of Open Models
Open-source models like DeepSeek V3.1 democratize AI, giving developers the freedom to deploy locally, integrate into unique workflows, and customize for niche use cases. This freedom comes at the price of greater responsibility, but it also lowers the barrier to global innovation.
Strategic Choices for Enterprises
The contrast forces organizations to decide where their priorities lie: premium reliability and compliance, or cost-effective experimentation and scalability. In practice, many may adopt a hybrid approach—using proprietary systems for sensitive tasks while turning to open models for broader innovation.
7. Enterprise Applications of DeepSeek V3.1
Software Development and Debugging
One of the clearest use cases is programming support. DeepSeek V3.1 can generate, review, and debug code at scale, integrating directly into developer workflows. With high accuracy and minimal syntax errors, it reduces the time spent on repetitive coding tasks.
Research and Education
Academic institutions and research organizations benefit from the model’s ability to process large volumes of text. Its extended context length enables detailed analysis of technical papers, structured summaries, and even interactive tutoring sessions. For schools and universities, this opens affordable opportunities to enrich learning experiences.
Business Process Automation
Enterprises can integrate the model into customer service, documentation management, and internal knowledge systems. Its coherence across long conversations makes it useful for chatbots and virtual assistants, where consistency and context retention are crucial.
Multilingual Capabilities
With its broad language training base, the model is well suited for international organizations. It can support communication across regions, assist in localization, and ensure that teams working in different languages have access to the same AI-powered tools.
8. Challenges and Limitations of DeepSeek V3.1
Infrastructure Demands
Running a 685-billion-parameter model requires significant hardware. Even with efficiency gains from Mixture-of-Experts, organizations may need advanced GPUs or specialized infrastructure, which could limit accessibility for smaller teams without cloud-based solutions.
Reliability and Stability
Closed-source competitors benefit from constant fine-tuning and professional support. Open-source models, by contrast, place more of the responsibility on the user. Enterprises adopting DeepSeek V3.1 must be prepared to manage updates, address bugs, and implement safeguards independently.
Ethical and Governance Concerns
Open access brings opportunity, but it also increases the risk of misuse. Without centralized oversight, the model could be adapted for harmful purposes such as misinformation campaigns or generating restricted content. This makes governance and responsible use critical factors in deployment.
Hidden Costs
While the cost-per-task is low, total expenses can rise when infrastructure, maintenance, and integration are taken into account. Enterprises need to weigh these hidden costs carefully to ensure they still achieve the long-term value promised by the model’s affordability.
9. The Future of Open-Source AI Competition
Pressure on Proprietary Leaders
The release of DeepSeek V3.1 places direct pressure on companies like OpenAI, Anthropic, and Google. They must justify premium pricing by delivering more than raw capability—focusing instead on refined reasoning quality, compliance, and reliability that open systems cannot yet guarantee.
Raising the Open-Source Standard
For the open-source ecosystem, V3.1 becomes a new benchmark. It shows that community-driven initiatives can operate at frontier scale, inspiring further projects to push toward even greater efficiency, specialization, and domain-specific adaptations.
Global Accessibility
The affordability of DeepSeek V3.1 broadens access to powerful AI for nations, startups, and organizations that cannot afford proprietary licenses. This democratization accelerates innovation but also raises questions about oversight and responsible use on a global scale.
Toward a Hybrid Future
Looking ahead, the industry is unlikely to converge on one model type. Instead, the landscape points toward a hybrid approach—with proprietary systems used for high-stakes applications and open models like DeepSeek adopted for scalable, cost-sensitive innovation.
10. Conclusion: Why DeepSeek V3.1 Is a Turning Point
Redefining Affordability
By offering coding support at just over a dollar per task, DeepSeek V3.1 redefines the economics of AI adoption. It opens opportunities for organizations that were previously excluded from frontier models due to cost.
Expanding the Open-Source Movement
The model represents more than technical progress; it embodies the momentum of open innovation. Its release strengthens the case that advanced AI should not be restricted to a few corporations but shared with a wider community.
Challenges Ahead
DeepSeek V3.1 is not without hurdles. Infrastructure demands, reliability concerns, and governance issues remain. However, these challenges are not insurmountable and can be mitigated through community collaboration and enterprise adaptation.
A Signal of Change
Above all, the release signals a shift in the AI ecosystem. Frontier-scale power is no longer confined to closed, high-cost platforms. DeepSeek V3.1 shows that open-source AI can stand toe-to-toe with the most advanced proprietary systems, marking a genuine turning point in the global race for artificial intelligence.
📚 References
- Analytics India Mag. (2025). DeepSeek releases V3.1 model with 685 billion parameters on Hugging Face. https://analyticsindiamag.com
- VentureBeat. (2025). DeepSeek V3.1 just dropped—and it might be the most powerful open AI yet. https://venturebeat.com
- Dev.to. (2025). DeepSeek V3.1 Complete Evaluation Analysis: The New AI Programming Benchmark for 2025. https://dev.to
- Technode. (2025). DeepSeek upgrades V3 model with more parameters, open-source shift. https://technode.com
- Medium. (2025). DeepSeek V3.1: A Deep Dive into the New Hybrid All-in-One Model. https://medium.com
- 36Kr Europe. (2025). DeepSeek’s V3.1 model challenges top AI benchmarks. https://eu.36kr.com
- AllThings.How. (2025). China’s DeepSeek releases model V3.1 with 685B parameters. https://allthings.how
- Arxiv.org. (2025). DeepSeek V3 Technical Report: Multi-head Latent Attention and Efficient MoE Scaling. https://arxiv.org
- Wikipedia. (2025). DeepSeek. Retrieved from https://en.wikipedia.org/wiki/DeepSeek
- Financial Times. (2025). China’s DeepSeek challenges US AI leaders with open-source supermodel. https://ft.com
🔑 Meta Keywords
DeepSeek V3.1, DeepSeek AI model, 685B parameter AI, open-source large language model, Aider coding benchmark, GPT-5 vs DeepSeek, Claude Opus vs DeepSeek, cost of AI coding tasks, open-source AI 2025, future of AI competition, 딥시크 AI 모델, 6850억 매개변수 AI, 오픈소스 대형 언어 모델, Aider 코딩 벤치마크, GPT-5와 DeepSeek 비교, Claude Opus와 DeepSeek 비교, AI 코딩 작업 비용, 2025 오픈소스 AI, AI 경쟁의 미래





