
Efficiency vs. Power: How DeepSeek V3.2 Is Challenging the AI Giants
The Model That Cuts AI Costs in Half: Inside DeepSeek V3.2-Exp
Discover how DeepSeek V3.2 challenges AI giants with cost-cutting tech, open-source access, and a bold shift toward efficient large language models.

For years, the AI race has centered on scale—bigger models, more GPUs, and massive training data. But a growing number of researchers and startups are starting to ask a different question: What if efficiency matters more than raw power?
DeepSeek V3.2, the latest model from Chinese AI startup DeepSeek, offers an answer. Officially named DeepSeek-V3.2-Exp, this experimental release isn’t chasing size for its own sake. Instead, it focuses on doing more with less.
While companies like OpenAI and Google DeepMind continue to push the boundaries of model size, DeepSeek is building smarter architecture designed to run faster, cheaper, and lighter. Its innovations—most notably DeepSeek Sparse Attention (DSA)—cut costs and compute requirements without compromising usability.
This blog breaks down what DeepSeek V3.2 is, how it works, and why it’s gaining attention as a serious alternative to heavyweight LLMs. Whether you’re a developer, researcher, or just tracking the future of AI, DeepSeek’s efficiency-first approach is worth watching.
1. What Is DeepSeek V3.2?
DeepSeek V3.2, officially released as DeepSeek-V3.2-Exp, is an experimental large language model from Chinese AI startup DeepSeek. Rather than chasing bigger model sizes, DeepSeek is focused on a different goal: delivering performance through efficiency.
A Shift Toward Leaner AI
While most large language models aim to scale up, DeepSeek V3.2 is built to scale smart. Its architecture emphasizes reduced compute, faster processing, and more efficient use of memory. This makes it better suited for real-world deployment, especially in settings where cost and infrastructure matter.
DeepSeek Sparse Attention (DSA)
At the core of the model is DeepSeek Sparse Attention, or DSA. Unlike traditional dense attention mechanisms, which treat every token equally, DSA identifies the most relevant key-value pairs and focuses attention only where it matters. This reduces computational load while maintaining strong output quality.
Hardware Flexibility
DeepSeek V3.2 isn’t limited to high-end U.S. chips. It runs natively on Chinese-designed processors like Ascend and Cambricon, which gives it a strategic advantage in environments where access to NVIDIA hardware is restricted or expensive.
Open-Source and Developer-Friendly
DeepSeek has also made the model open-source. That means developers and researchers can download the model, access the configuration files, and run or fine-tune it on their own systems. This level of accessibility lowers the barrier to entry for anyone looking to work with large language models without needing massive cloud infrastructure.
In short, DeepSeek V3.2 isn’t just efficient—it’s strategic, flexible, and open, making it one of the most developer-friendly models in the market today.
2. The Technology Behind DeepSeek V3.2
What makes DeepSeek V3.2 different isn’t just what it can do, but how it’s built. The model introduces a series of architecture-level optimizations that allow it to run faster and cheaper without losing performance.
Sparse Attention at the Core
The most important innovation is DeepSeek Sparse Attention (DSA). Traditional attention mechanisms compute relationships between every token in a sequence, which becomes expensive as inputs grow longer. DSA changes that by selecting only the most relevant tokens for each query.
This sparse pattern reduces the amount of memory and compute needed for inference, which directly cuts costs and speeds up response times. It’s especially useful for tasks like document summarization or long conversations, where context length is critical.
Lightning Indexer and Top-k Filtering
To enable sparse attention, DeepSeek V3.2 uses a module called the Lightning Indexer. It ranks which key-value pairs are worth attending to, using a lightweight scoring system combined with partial positional encoding. The model then keeps only the top-k entries.
This selective process avoids unnecessary computation and improves scalability without adding much complexity.
Multi-Query Attention (MQA)
The model also incorporates multi-query attention, which allows all attention heads to share the same set of keys and values. This further cuts down memory use and makes the model more efficient during both training and inference.
Built for Flexibility
Together, these components make DeepSeek V3.2 more than just a smaller model. They make it adaptable. It handles longer contexts, runs on a wider range of hardware, and maintains performance where traditional models would require far more compute.
3. Pricing Power: How DeepSeek V3.2 Reduces Costs
Alongside its technical design, DeepSeek V3.2 makes an even stronger case in the one place that matters to most users—price. It offers some of the most competitive rates in the AI space, especially for output-heavy applications.
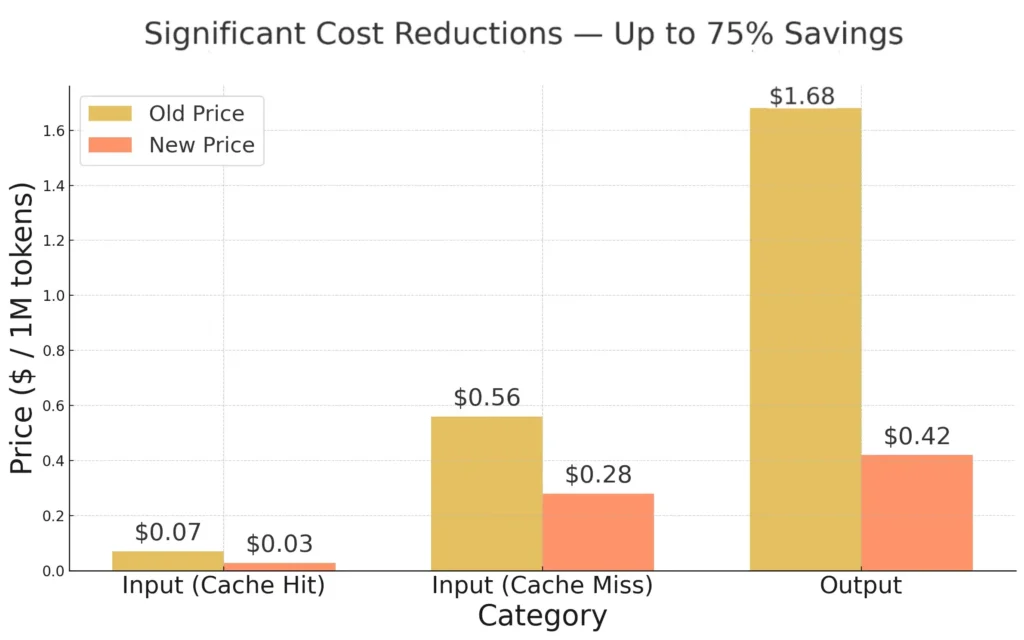
Token Pricing Breakdown
As of September 29, 2025, DeepSeek V3.2 API pricing is:
- Input (Cache Hit): $0.028 per 1 million tokens
- Input (Cache Miss): $0.28 per 1 million tokens
- Output: $0.42 per 1 million tokens
Compared to leading models like GPT-4 Turbo, which costs around $10 per million output tokens, DeepSeek V3.2 is dramatically more affordable.
Why It’s Cheaper
The savings aren’t just promotional. They come directly from the model’s design. Because DeepSeek V3.2 uses sparse attention and multi-query attention, it requires less compute per token. That means it costs less to run, and those savings get passed on to users.
Cache Efficiency
If your application reuses input—like a prompt template, static instruction, or long document—the cache hit pricing drops the cost even further. At under three cents per million tokens, DeepSeek offers one of the lowest processing rates of any commercial-grade API.
Real-World Impact
Lower pricing makes it easier for:
- Startups to experiment without burning budgets
- Researchers to scale experiments
- Developers to run models locally or in resource-constrained environments
For teams looking to scale AI without scaling infrastructure, DeepSeek V3.2 creates new possibilities that weren’t practical with more expensive models.
4. Who Should Care About DeepSeek V3.2?
DeepSeek V3.2 isn’t just a new model. It’s a signal that high-performance AI is becoming more accessible, affordable, and adaptable. But who stands to benefit most from this shift?
Startups and Indie Developers
For startups building AI-powered products, model cost is often the biggest roadblock. DeepSeek V3.2 dramatically lowers the barrier to entry, making it possible to build, test, and iterate without relying on VC-sized infrastructure budgets. Its open-source availability also means you can deploy on your own terms.
Researchers and Academic Teams
With token pricing far below the industry standard, researchers can afford to run more experiments and work with larger datasets. DeepSeek V3.2 also supports long-form context and multiturn interactions, making it well-suited for tasks like summarization, retrieval, or dialogue modeling.
AI Engineers in Cost-Constrained Markets
In regions where access to cloud infrastructure or NVIDIA chips is limited, DeepSeek’s support for Chinese-made AI hardware like Ascend and Cambricon opens up valuable alternatives. This flexibility matters for enterprises building sovereign AI stacks or governments pursuing tech independence.
Companies Focused on Efficiency and Local Deployment
If your team is prioritizing on-device AI, edge computing, or private deployments, DeepSeek V3.2’s efficient architecture and open-source tooling make it a compelling option.
5. DeepSeek V3.2 vs Traditional AI Models
While companies like OpenAI, Anthropic, and Google DeepMind continue to scale their models to new heights, DeepSeek V3.2 is quietly challenging the status quo by rethinking what matters most — not raw power, but smart, efficient design.
Sparse vs Dense Attention
Most major language models use dense attention, which processes every token in relation to every other token. This gets expensive fast, especially with long inputs. DeepSeek V3.2 takes a different route, using sparse attention to focus only on relevant parts of the input. This reduces computational overhead without sacrificing performance for most practical tasks.
Practical Affordability
DeepSeek V3.2 is not only more efficient in design — it’s also significantly cheaper to run. Compared to premium models like GPT-4, DeepSeek’s pricing offers up to 95% savings, especially for applications that generate a high volume of output tokens. This kind of affordability makes it accessible to startups, educators, and developers who need to scale.
Openness and Deployment Flexibility
Unlike many closed-source models tied to proprietary infrastructure, DeepSeek V3.2 is open-source and supports non-NVIDIA hardware like Ascend and Cambricon chips. This opens new deployment options — from local servers to sovereign AI stacks — without vendor lock-in.
Designed for Today’s Challenges
DeepSeek V3.2 may not outperform GPT-4 in abstract reasoning or open-ended creativity, but for real-world use cases — summarization, classification, document parsing, and chatbot logic — it offers a faster, leaner alternative.ss is rare in a landscape dominated by closed ecosystems.
6. What’s Next for DeepSeek?
While DeepSeek V3.2 is labeled as experimental, it’s already proving competitive in cost, performance, and accessibility. But DeepSeek isn’t stopping here.
In its official release notes, the company described V3.2-Exp as a “stepping stone” toward its next-generation architecture. That suggests even more ambitious developments are underway—potentially models that combine sparse attention with new training methods, multilingual capabilities, or better reasoning.
Given its rapid development cycle (from R1 to V3.2 in under two years), DeepSeek is positioning itself as a serious contender in the global AI race—not by outspending others, but by out-optimizing them.
Its open-source approach also hints at a long-term strategy: building a strong developer community around its tools and inviting others to co-create the ecosystem.
If future versions continue to push the boundaries of efficiency without sacrificing usability, DeepSeek may not just challenge the giants—it could reshape the way AI infrastructure is built worldwide.
7. Conclusion
As the AI world grows more crowded, DeepSeek V3.2 stands out by doing less — smarter. It doesn’t chase extreme model size or GPU-heavy deployment. Instead, it bets on architectural efficiency, open access, and real-world usability.
From sparse attention to flexible pricing, DeepSeek V3.2 shows that power isn’t just about performance benchmarks. It’s about accessibility, adaptability, and cost.
Whether you’re a developer building a startup, a researcher on a budget, or an engineer working on sovereign AI infrastructure, this model offers a viable alternative to the dominant players.
The question isn’t whether DeepSeek can compete. It’s whether the rest of the industry is ready to follow its lead.





