
The Revolutionary GPT-5 Architecture: Redefining AI Through Scaling, Memory, and Autonomy
Why GPT-5 Matters in the AI Race
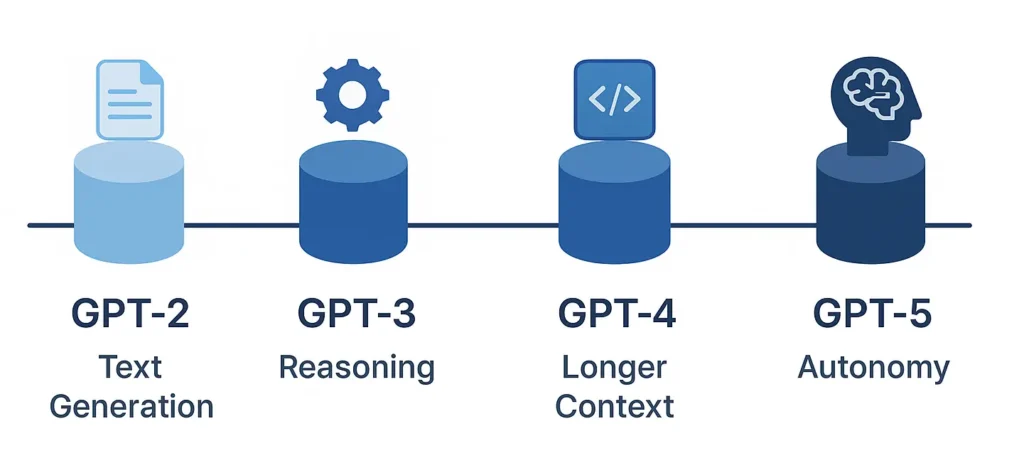
GPT-5 is not just a bigger model. It represents a turning point in how artificial intelligence is architected. While GPT-3 introduced large-scale language modeling and GPT-4 expanded reasoning and context length, GPT-5 is expected to bring fundamental changes to the way AI systems are structured, scaled, and deployed.
What sets GPT-5 apart is its architectural focus on three core capabilities: scaling smarter, remembering longer, and operating more autonomously. These are not surface-level improvements. They reflect a shift from reactive models to systems designed for cognitive flexibility, persistent memory, and real-time task planning.
This blog explores what is likely inside the GPT-5 architecture based on current research trends, OpenAI’s recent releases, and industry benchmarks. You’ll gain insight into how GPT-5 handles computation through expert routing, how it integrates memory systems for continuity across sessions, and how it sets the foundation for AI agents that plan and act on their own.
The technical figure below traces this evolution and shows how each generation has moved closer to general-purpose, reasoning-capable AI. It provides a schematic overview of GPT-2 through GPT-5, highlighting the architectural transitions from simple generation to advanced reasoning, sparse expert routing, and emerging autonomy.
The Blueprint of GPT-5 Architecture
The GPT-5 architecture represents a shift from traditional dense transformer blocks toward a more efficient and modular system centered on the Mixture of Experts (MoE) design. Instead of activating the entire model for every input, GPT-5 selectively routes data through a small set of specialized expert networks. This improves scalability, reduces computational demands, and enhances task-specific performance.
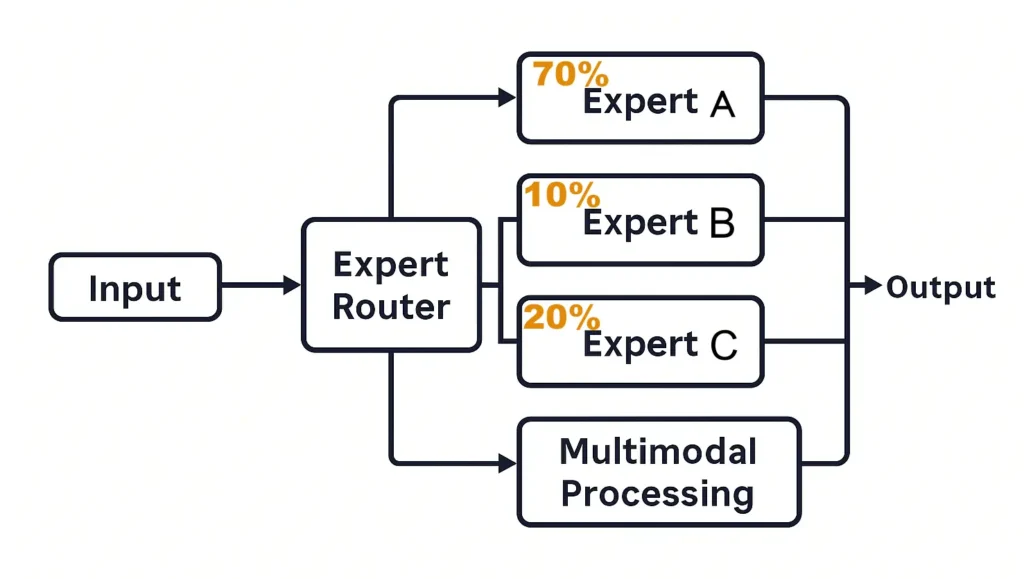
As illustrated in Figure 2, incoming inputs are first analyzed by an Expert Router, which determines the most appropriate experts for the task. In the example, Experts A, B, and C are activated in specific proportions such as 70%, 10%, and 20%. This task-driven routing means that only a few experts are used per forward pass, allowing the system to conserve resources without sacrificing quality.
This design also enables GPT-5 to scale to over a trillion parameters without requiring a linear increase in compute. Additionally, it lays the groundwork for multimodal integration. A dedicated Multimodal Processing module can handle text, images, and potentially audio or video inputs within a unified architecture.
Altogether, this structure makes GPT-5 flexible, adaptive, and highly efficient. The model is not simply bigger than its predecessors. It is engineered to gain performance through intelligent architecture rather than brute-force scale.
Scaling Smarter: Mixture of Experts and Modular Intelligence
One of the most transformative aspects of the GPT-5 architecture is how it approaches scaling. Rather than deepening every layer or increasing every matrix uniformly, GPT-5 focuses on selective activation and modular intelligence. This is made possible through the Mixture of Experts (MoE) framework, which allows the model to reach over a trillion parameters while using only a small portion during each inference.
In contrast to dense transformer models, where every token flows through all layers, GPT-5 dynamically routes each input through a small set of specialized expert blocks. Each expert is fine-tuned for a particular class of tasks, such as reasoning, summarization, programming, or translation. The Expert Router, as illustrated in Figure 2, analyzes the input and selects the most relevant combination of experts. Typically, only 2 to 4 experts are activated from a pool that may contain over 100.
This sparse activation strategy provides two primary advantages:
- Computational Efficiency: GPT-5 can scale up in size without a proportional increase in compute for each query.
- Task Specialization: Individual experts develop deeper capabilities in specific domains, improving output quality on varied inputs.
In addition, GPT-5 likely supports dynamic token-level routing, which means different sections of a long input can be processed by different expert combinations. This gives the model more contextual awareness and adaptability.
Together, these architectural choices reflect a broader shift in AI design. GPT-5 moves away from a monolithic structure and embraces a modular, flexible, and scalable form of intelligence that is better suited to complex, real-world tasks.
Redefining Memory: Beyond Token Limits to Long-Term Context
One of the most significant innovations in the GPT-5 architecture is its approach to memory. Earlier models such as GPT-3 and GPT-4 relied entirely on static context windows. GPT-3 supported around 2,048 tokens, and GPT-4 Turbo extended that limit to approximately 128,000 tokens. While these expansions allowed for more information in a single prompt, they still did not create true memory or continuity between interactions.
GPT-5 is expected to advance beyond static limits by combining extended context windows, retrieval-augmented memory, and persistent session memory. This will enable the model to retain useful information from prior interactions and dynamically reference it as needed. Rather than relying on prompt repetition or retraining, GPT-5 will likely retrieve relevant data from an external memory index based on semantic similarity.
In practice, this may involve embedding prior user interactions into latent vector representations, storing them in a searchable memory bank, and retrieving them during future sessions when context continuity is required. This mechanism resembles retrieval-augmented generation (RAG) but is expected to be implemented directly within GPT-5’s core architecture.
More importantly, GPT-5 is likely to support long-horizon memory. This allows it to maintain state across tasks or sessions, enabling multi-step reasoning and personalization over time.
For developers and end users, this evolution means less repetition, smoother interactions, and the foundation for AI systems that behave with coherence and foresight. It positions GPT-5 not just as a model that understands input, but one that remembers and adapts with purpose.
Architecting Autonomy: From Reactive Chatbot to Cognitive Agent
Although GPT-3 and GPT-4 demonstrated impressive fluency and reasoning capabilities, they remained fundamentally reactive. These models responded to prompts without internal goals, persistent memory, or the ability to plan across multiple steps. In contrast, the GPT-5 architecture introduces design elements that support autonomous behavior.
At the heart of GPT-5 is likely a system that enables task decomposition, decision-making, and tool use. These are foundational components of what is often referred to as agentic AI. GPT-5 may be capable of identifying multi-step objectives, determining when to call external tools such as calculators or databases, and refining its responses based on intermediate results.
Structurally, GPT-5 may operate through a recurring decision loop. This loop involves understanding the task, generating a plan, executing individual substeps, and updating its strategy based on outcomes at each stage.
Rather than returning a single static output, GPT-5 may pause mid-process to retrieve information, invoke a function, or consult its internal memory. This behavior mirrors the logic of emerging systems like ReAct, Toolformer, and AutoGPT. However, GPT-5 is expected to implement these capabilities as part of its core architecture rather than relying on external prompt engineering.
The use of persistent memory and expert routing enhances this capability further. Specific experts could be dedicated to managing goals, coordinating tool use, or interpreting environmental cues. This design transforms GPT-5 from a responsive chatbot into a cognitive agent that can act, adapt, and complete complex objectives.
Such autonomy has the potential to redefine how AI systems operate, shifting from reactive assistants to proactive collaborators across software platforms and real-world workflows.it reimagines how AI integrates into software, workflows, and decision systems.
Training the Titan: What Powers GPT-5 Behind the Scenes
The advanced capabilities of the GPT-5 architecture, including expert routing, extended memory, and autonomous behavior, are the result of an enormous increase in training scale. GPT-5 is not only smarter by architectural design but is also trained with an unprecedented volume of compute, data, and system-level optimization.
Analysts estimate that GPT-5 may have been trained on between 10 and 100 trillion tokens, sourced from curated web content, technical papers, synthetic data generated by earlier models, and multimodal formats such as images and code. This wide-ranging dataset supports GPT-5’s ability to generalize and reason across varied tasks and domains.
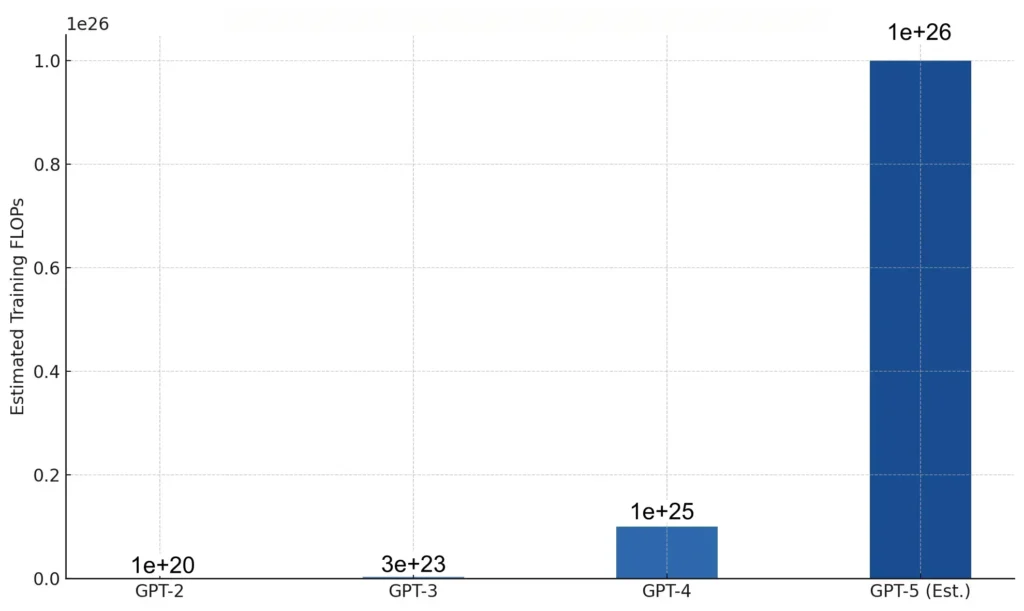
The computational footprint behind GPT-5 is even more striking. GPT-3 required approximately 3 × 10²³ floating-point operations (FLOPs), and GPT-4 likely exceeded 10²⁵. GPT-5 is believed to have gone well beyond that, potentially surpassing 10²⁶ FLOPs. Achieving this scale required distributed training infrastructure, custom accelerators like TPUs or GPUs, and optimized frameworks for memory management, sparse activation, and efficient routing.
Another critical improvement is training efficiency. GPT-5 does not update every parameter with each training step. Instead, it selectively refines only the most relevant expert pathways, which reduces energy consumption and allows each expert to specialize further.
To illustrate the evolution in scale, Figure 3 provides a visual comparison of the training compute required by GPT-2 through GPT-5. The growth reflects how architectural breakthroughs and hardware innovation together enabled GPT-5’s leap forward.
Comparing GPT-5 and GPT-4: Architectural Evolution in Action
GPT-4 introduced major advancements in reasoning, multimodal capability, and context length. However, it remained a dense transformer model with a fixed structure and limited internal flexibility. The GPT-5 architecture, in contrast, introduces new principles that make it more adaptive, efficient, and capable of autonomous behavior.
The table below highlights key architectural differences between GPT-4 and GPT-5. These distinctions go beyond size and compute, revealing a shift in how intelligence is organized and deployed inside the model.
Table 1. GPT-4 vs GPT-5: Architectural Comparison
| Feature | GPT-4 | GPT-5 (Expected) |
|---|---|---|
| Model Type | Dense Transformer | Sparse Mixture of Experts (MoE) |
| Activation Strategy | All layers always active | Only relevant experts activated per token |
| Context Window | Up to 128k tokens | Up to 256k+ tokens + memory retrieval |
| Memory | Stateless (session-based) | Persistent + Retrieval-Augmented |
| Autonomy | Reactive prompt → response | Task planning, tool use, feedback loops |
| Multimodal Integration | Add-on vision module | Native multimodal core |
These upgrades in the GPT-5 architecture provide a foundation for more general purpose, adaptive, and agent-like AI systems. GPT-5 is not just more powerful. It is built differently to serve a broader range of applications with higher contextual intelligence.
Implications for Developers, Enterprises, and the Future of Work
The introduction of the GPT-5 architecture is not just a technical milestone. It marks a strategic shift in how organizations will build, integrate, and rely on AI systems. With features like expert routing, long-term memory, and autonomous reasoning, GPT-5 opens new possibilities for developers and enterprises alike.
For software engineers and AI practitioners, GPT-5 introduces a model that can handle more complex workflows with fewer engineering constraints. Its modular design allows for finer control over performance, efficiency, and task specialization. Developers can build applications that tap into specific expert pathways or integrate memory systems that persist across user sessions.
In enterprise environments, GPT-5 will likely enhance the role of AI across departments. Sales teams can benefit from agents that recall past interactions. Legal and compliance teams can delegate document review to expert-tuned subsystems. Executives can use AI copilots that analyze data, ask clarifying questions, and provide actionable summaries without human prompting.
GPT-5’s architecture supports this shift by combining flexibility with continuity. It enables AI tools to operate less like static assistants and more like collaborative, goal-oriented systems that evolve with users and adapt to context.
This change redefines productivity, decision-making, and digital strategy at every level, from individual contributors to enterprise-wide operations.
Conclusion: The Architectural Shift That Sets a New Standard
The GPT-5 architecture is more than an iteration. It represents a complete redesign of how large language models are structured, scaled, and applied. From sparse expert routing to persistent memory and agent-like autonomy, GPT-5 shifts the focus from size alone to intelligent design.
These changes are not theoretical. They are already influencing how developers build tools, how enterprises deploy automation, and how users interact with digital systems. GPT-5 introduces a blueprint for scalable, adaptable, and context-aware AI that can serve as the foundation for autonomous agents and intelligent infrastructure.
As AI moves deeper into daily life and critical systems, architecture will matter more than ever. GPT-5 sets a new standard by making that architecture smarter, leaner, and more aligned with how intelligence should function.
📚 References
- OpenAI. (2023). GPT-4 Technical Report
https://openai.com/research/gpt-4 - Shazeer et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
https://arxiv.org/abs/1701.06538 - Lepikhin et al. (2020). GShard: Scaling Giant Models with Conditional Computation
https://arxiv.org/abs/2006.16668 - Fedus et al. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
https://arxiv.org/abs/2101.03961 - Chen et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools
https://arxiv.org/abs/2302.04761 - Yao et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models
https://arxiv.org/abs/2210.03629 - Google DeepMind. (2024). Gemini 1.5: Scaling, Memory, and Multi-Modality
https://deepmind.google/technologies/gemini/ - OpenAI. (2024). ChatGPT Memory and Custom Instructions
https://help.openai.com/en/articles/7730893-about-chatgpt-memory - Microsoft Research. (2023). Phi-2: Scaling Instruction Tuning
https://www.microsoft.com/en-us/research/publication/phi-2/
✅ Keywords
- gpt-5 architecture
- mixture of experts
- sparse expert routing
- gpt-5 memory system
- long context language models
- retrieval augmented generation
- gpt-5 vs gpt-4
- autonomous ai agent
- ai model scaling
- multimodal transformer
- persistent ai memory
- gpt-5 training compute
- token-aware routing
- gpt-5 technical breakdown
- ai model architecture
- gpt-5 roadmap
- modular intelligence
- future of large language models
- openai gpt-5
- next-gen ai design





