
Gemini 2.5 AI and the Rise of Artificial Intelligence That Uses Computers Like Humans
Meet the AI That Can Use a Computer Better Than You
Gemini 2.5 AI is Google’s latest breakthrough: an AI model that can navigate websites, click, type, and use computers like a human. Explore how it works and what it means for the future of automation.
Until recently, artificial intelligence was limited to generating content or answering questions. It could assist with ideas, write emails, summarize reports, or hold a conversation, but it could not take real action. Gemini 2.5 AI, Google’s latest breakthrough, changes that.
This model does more than understand language. It sees what is on your screen, interprets buttons, forms, and layouts, and takes real actions like clicking, typing, and scrolling. In short, it uses a computer the same way you do.
With this shift, Google has introduced an AI that can perform real work inside web and mobile applications. It can complete multi-step workflows, handle dynamic interfaces, and adapt to changing layouts in real time.
Early results show a significant jump in speed and accuracy. Testers report workflows running 50 percent faster and with fewer errors compared to previous tools. The possibilities for automation, support, testing, and productivity are massive.
In this post, we will look at what Gemini 2.5 AI is, how it works, what makes it different, and why it signals the beginning of a new era in AI-powered computing.
1. Understanding the Gemini 2.5 Computer Use Model
Google’s Gemini 2.5 family includes different versions for different use cases. The Gemini 2.5 Pro model powers consumer tools like Google Chat and Workspace. This article focuses on Gemini 2.5 Computer Use, a specialized capability within the Gemini platform that enables the AI to control websites and apps through visual input and real-time action. For clarity and consistency, we refer to this as Gemini 2.5 AI throughout the article.
Moving Beyond Text-Based AI
Most AI systems focus on generating language. They respond to prompts, summarize documents, or analyze data. But they cannot click buttons, type into fields, or navigate apps. Gemini 2.5 AI changes that by combining visual input, reasoning, and action.
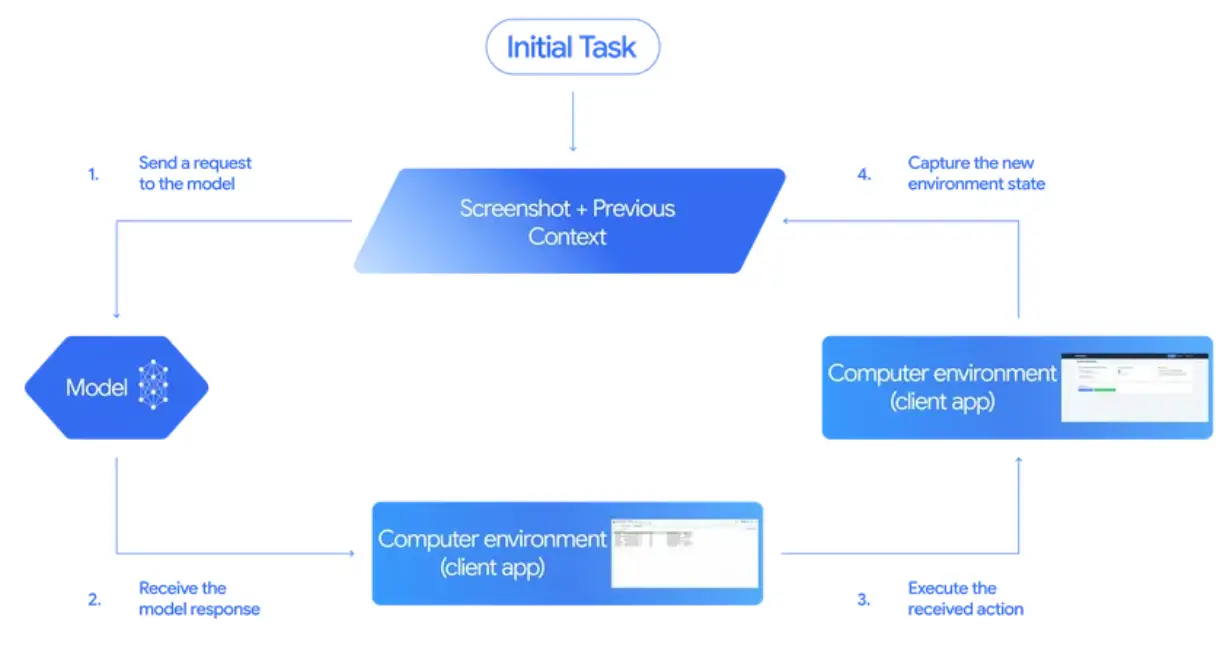
It works with a loop of screenshots and actions. The AI receives an image of the screen, decides what to do next, and takes a step. That step could be a click, scroll, or typed input. Then it gets a new screenshot and repeats the process until the task is complete.
Built for Web and App Interaction
Gemini 2.5 AI is designed to work inside browsers and mobile apps. It does not rely on APIs or backend systems. Instead, it interacts directly with what is visible on the screen. This allows it to:
- Fill out complex forms
- Navigate multi-step workflows
- Search and interact with web content
- Handle dynamic elements like popups or modals
The model understands visual structure rather than relying on code. This makes it useful in environments where automation tools often fail. Gemini 2.5 Computer Use has also demonstrated stronger performance than other leading models, including OpenAI’s Computer Using Agent and Anthropic’s Claude Sonnet 4.5 and 4, across both web and mobile interface benchmarks.
A Foundation for Autonomous Agents
Gemini 2.5 AI is part of a larger shift in artificial intelligence. Rather than staying passive and waiting for instructions, it is built to complete tasks independently. It can follow a chain of actions, maintain memory of past steps, and work toward a clear goal.
This moves AI closer to becoming a true digital worker — one that can operate software, solve problems, and support users through direct interaction with the tools they use every day.s, and productivity seekers, this opens the door to building AI systems that handle routine tasks, test applications, and eventually operate software autonomously.
2. How Gemini 2.5 Uses Computers Like Humans
What sets Gemini 2.5 AI apart is its ability to interact with a digital interface the same way a person would. Instead of relying on code or hidden APIs, it looks at what is on the screen, understands what needs to be done, and takes action through a loop of observation and response.
Visual Understanding of the Interface
Gemini 2.5 AI receives a screenshot of the current browser or app view. It analyzes the visual layout, identifies buttons, menus, text fields, and other elements, then determines what action is needed based on that input. It does not need to access the underlying HTML or know how the site is coded. It makes decisions based on what it sees, just like a user would.
The model also uses a short history of recent actions to maintain context as it works through a task. This allows it to adapt to multi-step workflows with changing layouts or dynamic content.
A Closed-Loop Action Cycle
Gemini operates in a repeating cycle:
- It receives a screenshot and a list of recent actions.
- It predicts the next best action, such as click, type, or scroll.
- The action is executed by the system.
- A new screenshot is captured and sent back to the model.
- The cycle continues until the task is complete or canceled.
This step-by-step approach gives the model flexibility and control. It does not need to solve the entire task at once. It just needs to make the next correct move based on what is in front of it.
Human-Like Interaction Patterns
Unlike bots that rely on fixed selectors or code-based instructions, Gemini 2.5 AI interacts with the interface visually. It clicks buttons based on their appearance, types into the right fields by recognizing placement, and scrolls when necessary to find elements that are off-screen.
This makes it highly adaptable. It can handle websites and apps that change frequently, use dynamic layouts, or do not expose data in structured formats. The model behaves more like a trained assistant using a keyboard and mouse than a traditional automation script.
3. What Makes Gemini 2.5 AI Different (and Better)
Gemini 2.5 AI stands out not just for what it can do, but for how it does it. While other tools rely on scripts, plugins, or APIs, this model interacts with digital environments visually and contextually, much like a human. That makes it more adaptable, more responsive, and better suited for real-world use.
Designed for Real Interfaces
Most automation tools depend on structured HTML, consistent element IDs, or clean code. If something changes on the page, the automation breaks. Gemini 2.5 AI avoids that problem by reading the screen as an image and interpreting what it sees.
This gives it the flexibility to work with:
- Websites that change often
- Mobile interfaces
- Platforms with poor or no API support
- Custom UIs that were never meant to be automated
Performance That Beats the Competition
Google claims Gemini 2.5 AI outperforms “leading alternatives” on benchmarks involving browser and mobile control. While full benchmark details haven’t been made public, early testers report up to:
- 50% faster task completion
- 18% higher accuracy on complex, multi-step workflows
This gives it a significant edge over traditional UI automation tools and even other AI agent models currently in development.
Low Latency, High Responsiveness
One of the biggest hurdles in AI-driven automation is lag. Long delays between steps can ruin user experience and make automation unusable at scale. Gemini 2.5 AI focuses heavily on keeping latency low, with a tight loop between observation and action.
The result: faster, more natural interaction patterns that feel closer to human behavior than robotic scripting.
Continuous Context Awareness
Unlike most bots or task runners that operate in isolated steps, Gemini 2.5 AI remembers recent actions and adjusts accordingly. This context tracking lets it:
- Resume partially completed tasks
- Recover from minor UI changes
- Make smarter decisions in workflows
Combined with its visual intelligence, this makes the model resilient and adaptive — a major requirement for scaling agentic AI in real-world environments.
4. Game-Changing Use Cases
The biggest value of Gemini 2.5 AI lies in how it can be applied. Because it operates through the interface like a human, it opens the door to automating work that used to require full user control. These are not theoretical examples. Early adopters are already building real tools around this model.
Web Automation Without APIs
Gemini 2.5 AI can automate tasks on websites that do not offer integrations. It does not need an API to log in, click buttons, or fill out forms. It sees the layout, identifies the task, and completes it.
Example tasks include:
- Logging into secure portals
- Filling multi-step forms
- Scraping structured data from messy layouts
- Completing actions that are not exposed through backend code
Smarter Testing and QA
Traditional testing tools rely on scripts that often break when the UI changes. Gemini 2.5 AI is different. It understands the layout visually and can interact with the app as if it were a real user.
This is useful for:
- Running UI tests without writing test scripts
- Navigating through apps to find bugs
- Validating layout and functionality through visual context
It reduces the time and maintenance needed for reliable testing.
AI That Acts as a Digital Assistant
Because it can perform tasks inside web or mobile apps, Gemini 2.5 AI could become the foundation for smarter digital assistants. Instead of just reminding you to book a flight, it can actually do it.
It could handle:
- Submitting expense reports
- Navigating dashboards
- Completing repetitive admin tasks
- Managing personal workflows across apps
It works with the tools you already use, through the same interfaces you click every day.
Support and Accessibility
Gemini 2.5 AI could make technology more accessible. It can act as a visual guide or co-pilot for users with physical limitations. By following voice instructions or automating manual steps, it could help people interact with digital systems more easily.
It can also assist support teams by simulating user sessions, testing workflows, or walking through complex issues in real time.
5. How Gemini 2.5 AI Compares to the Competition
Google isn’t the only company building agent-style AI, but Gemini 2.5 AI is setting a high bar. When compared to both traditional automation tools and other next-gen AI systems, its ability to visually understand and control interfaces gives it a clear edge in real-world usability.
Versus OpenAI’s Agents
OpenAI has hinted at similar capabilities with its experimental agents and function-calling APIs. While powerful, those systems still rely heavily on structured data, plugins, or API integrations to perform tasks.
Gemini 2.5 AI is different. It works by observing the screen and acting based on what it sees. It doesn’t need a plugin to log into a website or a predefined API to submit a form. That makes it more flexible, especially for interacting with messy, real-world websites.
Versus Anthropic’s Claude
Claude has also explored the idea of computer-use AI. However, Claude’s current models have not demonstrated full browser control with visual inputs and real-time action loops. Gemini 2.5 AI appears to be ahead in terms of executing tasks autonomously in a UI-driven environment.
Where Claude excels at safe and aligned text generation, Gemini 2.5 is focused on getting things done through interface interaction.
Versus Traditional Automation Tools
Legacy tools like Selenium, Puppeteer, or Robotic Process Automation (RPA) platforms require scripting, detailed selectors, and consistent UI structure. They break easily if something on the page moves or changes.
Gemini 2.5 AI doesn’t break the same way. It doesn’t care about CSS classes or IDs. It sees the interface the way a human does and adapts accordingly. This makes it far more robust for modern applications, especially those that update frequently or use dynamic content.
Versus Previous Gemini Models
Earlier versions like Gemini 1.5 were excellent at reasoning, summarizing, and multimodal input, but they didn’t have the ability to perform actions. Gemini 2.5 builds on that foundation with hands-on control, combining intelligence with agency.
This shift transforms Gemini from a smart assistant to an active digital worker.
6. Limitations and Challenges
As impressive as Gemini 2.5 AI is, it’s not perfect. The technology is still in preview, and like any early-stage system, it comes with real limitations and risks. Understanding these challenges is important before relying on it for critical tasks or integrating it into production workflows.
Accuracy Is Not Guaranteed
While early benchmarks show improved performance, Gemini 2.5 AI can still make mistakes. It may click the wrong button, misread the layout, or get stuck in a loop. Complex or cluttered interfaces can confuse the model, especially if elements overlap, change dynamically, or rely on JavaScript behavior that isn’t visually obvious.
This means it’s not yet reliable enough for unsupervised operation in all cases.
Security and Safety Concerns
Giving an AI control over your browser or app raises clear security questions. What if it submits the wrong form, deletes the wrong data, or clicks something it shouldn’t?
Google has published safety guidelines for developers using the computer_use tool. These include avoiding sensitive tasks like payments, data deletion, or security settings. But the potential for misuse or unintended consequences still exists.
Limited to UI Control
Gemini 2.5 AI is not a full system-level agent. It can’t control your desktop, manage files, or operate apps outside the browser or a mobile view. It doesn’t yet integrate with operating systems, file systems, or offline software.
In short, it’s powerful within the browser sandbox but not beyond it — at least for now.
Debugging and Transparency
When Gemini 2.5 AI fails to complete a task, it can be difficult to understand why. There is no console log or stack trace like in traditional automation tools. The model’s internal reasoning is opaque, which can slow down debugging and limit trust in critical workflows.
This makes it harder for teams to diagnose errors, especially in large-scale use cases.
7. Why This Signals a Shift in Human-Computer Interaction
Gemini 2.5 AI is more than a technical achievement. It represents a major change in how we think about AI and its role in digital work. Until now, most AI tools have stayed in the realm of conversation and content. This model crosses a line and begins to take action in real environments.
From Language Models to Digital Workers
Language models like ChatGPT, Claude, and earlier versions of Gemini focused on generating text, answering questions, and summarizing data. They were smart, but they needed a human to do the clicking, typing, and moving.
Gemini 2.5 AI bridges that gap. It does not just understand tasks, it completes them. It can follow a workflow, navigate through multiple steps, and reach an outcome without a human guiding every move.
This shift redefines the role of AI from assistant to operator.
The Rise of Interface-Native Automation
Instead of depending on APIs or backend access, Gemini 2.5 AI interacts directly with the same interfaces humans use. That makes it uniquely positioned for a world where not every tool or site is built with automation in mind.
It can work in places where API access is restricted, where UI changes often, or where no integration is available. That gives it flexibility traditional tools do not have.
Human and AI Collaboration, Not Replacement
The goal here is not to replace human workers. It is to give them support. Gemini 2.5 AI can handle the tedious, repetitive tasks so humans can focus on strategy, creativity, and decisions.
It becomes a digital teammate — one that does not need sleep, does not get bored, and works through the interface like any trained user would.
8. What’s Next for Gemini AI
Gemini 2.5 AI is just the beginning. While the current model focuses on web and app interfaces, it is clear that Google has bigger ambitions. What we are seeing now is a preview of how AI could operate across the entire digital stack.
Toward Full System-Level Control
Right now, Gemini 2.5 AI is limited to browser and mobile UI control. But the next logical step is expanding beyond the browser — into desktops, operating systems, and file systems.
Imagine an AI that can open documents, run software, manage local folders, or troubleshoot apps on your device. That kind of system-level agent could transform IT support, content creation, and digital operations at scale.
Deeper Integration with Google’s Ecosystem
As part of the Gemini platform, this model is likely to become more deeply integrated with Google Workspace, Chrome, Android, and even third-party SaaS tools. A future version could fill in spreadsheets, navigate Gmail, or update Google Ads campaigns — all through visual interaction.
Google has the platform reach to embed Gemini into productivity tools where AI action becomes seamless.
Smarter, More Autonomous Agents
As the loop between observation, action, and memory improves, future versions of Gemini could handle longer tasks with fewer prompts. They may be able to plan full sessions of work, take corrective actions when errors occur, and learn from user preferences over time.
The goal is not just a reactive AI, but a truly autonomous system that works alongside you across the tools you use every day.
9. Conclusion: The Start of Something Big
Gemini 2.5 AI is more than a step forward in artificial intelligence. It is a shift in how we think about what AI can actually do. Instead of just answering questions or generating content, this model can use computers the way people do. It can see the screen, understand the layout, and take real actions.
This opens the door to a new kind of digital assistant. One that does not just offer suggestions, but follows through. One that does not need backend access or special plugins, because it works with the same tools you do — through the interface.
There are still challenges. It is not perfect, and it is not ready for every situation. But it shows where the future is heading. AI is no longer just something you talk to. It is something you can work with.
If you are building, managing, or exploring the future of automation, Gemini 2.5 AI is a name you should know. This is the beginning of a smarter, more capable generation of AI.
And it is just getting started.





