
GPT-5 성능 논란의 진실: 샘 올트먼의 긴급 조치와 사용자 신뢰 회복 전쟁
OpenAI가 GPT-5 출시를 발표했을 때, 이는 단순한 AI 모델 업데이트 이상의 의미를 갖는 것으로 여겨졌습니다. 회사 역사상 가장 강력하고, 가장 다재다능하며, 가장 적응력이 뛰어난 시스템이 될 것이라는 자신감이 가득했습니다. 출시 전 몇 달 동안, 데모 영상과 성능 벤치마크 차트, 블로그 글을 통해 이전 주력 모델 대비 GPT-5 성능이 크게 향상되었다는 메시지가 지속적으로 나왔습니다. AI 업계에서는 이제 대형 언어 모델이 단순히 더 똑똑해지는 것을 넘어, 대화 속에서 더 “살아있는” 듯한 경험을 제공하는 전환점이 될 것이라는 기대가 퍼졌습니다.
OpenAI의 사전 홍보는 기대감을 한껏 끌어올렸습니다. 샘 올트먼 CEO와 임원들은 GPT-5가 더 풍부한 대화를 나누고, 복잡한 다단계 지시를 따르며, 사용자 스타일에 맞춰 말투를 조정할 수 있다고 강조했습니다. 또한 ‘Listener(경청자)’, ‘Nerd(덕후)’, ‘Cynic(냉소가)’ 등 새로운 성격 모드를 도입해 대화의 개성을 살렸습니다. 이 모든 홍보는 GPT-5가 GPT-4나 GPT-4o를 대체하는 수준을 넘어 완전히 새로운 차원으로 끌어올릴 것이라는 기대를 만들었습니다.
출시 당일이 되자, 분위기는 최고조에 달했습니다. 기술 매체들은 생중계로 소식을 전달했고, 수천 명의 개발자, 연구자, 일반 ChatGPT 사용자들이 8월 라이브스트림에 접속했습니다. 행사 자체는 세련되고 에너지가 넘쳤으며, GPT-5의 추론력, 정확성, 응답 속도 향상을 강조하는 데 집중했습니다. 특히 다양한 차트와 성능 지표를 통해 실사용 GPT-5 성능이 이전 모델을 압도한다는 인상을 주려 했습니다.
하지만 기대감은 오래가지 않았습니다. 출시 직후, 문제는 GPT-5가 모든 면에서 실패했기 때문이 아니라, 사용자 경험이 사전 홍보와 맞지 않았기 때문이었습니다. 기술적 오류가 시연을 가렸고, 모델의 응답은 때때로 지나치게 무미건조하거나 일관성이 떨어졌습니다. 가장 목소리가 큰 커뮤니티는 환호 대신 “이게 정말 GPT-4o보다 나은가?”라는 질문을 던지기 시작했습니다.
많은 사용자들에게 이것은 단순한 기대 과잉이 아니었습니다. 오히려 기술적으로 인상적인 동시에 사용하기에 만족스러운 제품을 OpenAI가 만들어낼 수 있는지에 대한 시험대가 되었습니다. 그래서 이 블로그에서는 실제로 무슨 일이 있었는지, OpenAI가 긴급 AMA에서 밝힌 비하인드 스토리, 그리고 모델과 평판을 모두 회복하기 위해 진행 중인 조치들을 파헤칠 것입니다. 이어지는 섹션에서는 출시 당일의 주요 문제와 그에 대한 대응을 분석하며, 가장 중요한 질문 즉, 일상적인 GPT-5 성능이 과연 기대에 부응하는가에 답해볼 것입니다.
1. 기술적 문제와 ‘차트 오류’
차트의 의도
OpenAI의 GPT-5 라이브스트림은 단순히 기능을 보여주는 자리가 아니라 신뢰를 구축하는 자리였습니다. 행사에서 공개된 다채로운 막대 차트는 GPT-5 성능 향상을 한눈에 보여주기 위해 제작되었습니다. 이 시각 자료는 일반 ChatGPT 사용자부터 업계 분석가까지 모두를 대상으로, GPT-5가 지금까지의 모델 중 가장 뛰어나다는 것을 쉽고 직관적으로 증명하려는 목적이 있었습니다.
무엇이 잘못되었나
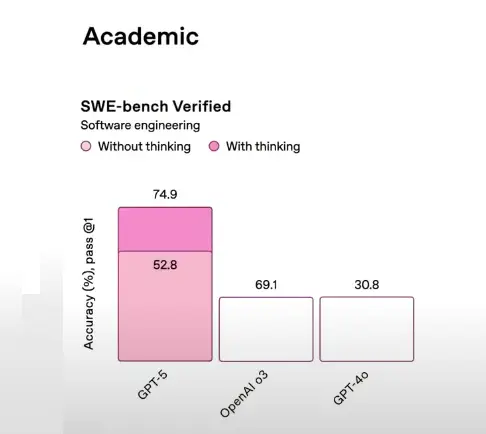
그러나 이 차트들은 신뢰를 높이기는커녕 오히려 PR 부담이 되었습니다. 시청자들은 숫자와 시각적 표현 사이에서 심각한 불일치를 빠르게 발견했습니다.
- 더 낮은 수치의 막대가 더 높은 수치의 막대보다 길게 표시됨.
- 예: GPT-5의 ‘기만율(deception rate)’이 50%인데, GPT-o3의 47.4%보다 막대가 짧게 표현됨.
- 또 다른 차트에서는 52.8%가 69.1%보다 긴 막대로 표시되는 등 비례 원칙이 깨짐.
이러한 불일치는 몇 분 만에 Reddit, X(구 트위터), Discord를 통해 퍼졌으며, “수학 법칙마저 바꾸는 AI” 같은 조롱 섞인 캡션과 함께 공유되었습니다.
OpenAI의 대응
샘 올트먼은 긴급 AMA에서 이 상황을 “메가 차트 실수(mega chart screwup)”라고 표현했습니다. 그는 기본 벤치마크 데이터 자체는 정확했지만, 차트의 비율과 형식이 제작 과정에서 잘못 처리되었다고 인정했습니다. OpenAI는 24시간 안에 다음 조치를 취했습니다.
- 공식 블로그의 잘못된 시각 자료 교체
- 간단한 공개 사과문 발표
- 향후 모든 대외 성능 데이터에 대해 더 엄격한 내부 검토 약속
신뢰에 미친 영향
차트는 단순한 장식이 아니라, 제품 발표에서 신뢰의 지표 역할을 합니다. 측정 가능한 개선을 입증해야 하는 발표에서, 의도치 않은 오류라도 의심을 불러올 수 있습니다. 일부 비평가들은 실사용 GPT-5 성능이 정말로 마케팅과 일치할지에 대해 의문을 제기하기 시작했습니다. 결과적으로, 이 ‘차트 오류’는 출시 초기의 실수를 상징하는 사건이 되었고, 실제 기술적 발전보다 부정적인 인상을 더 강하게 남겼습니다.
2. 오토스위처 장애와 성능 저하 인식
오토스위처의 의도된 기능
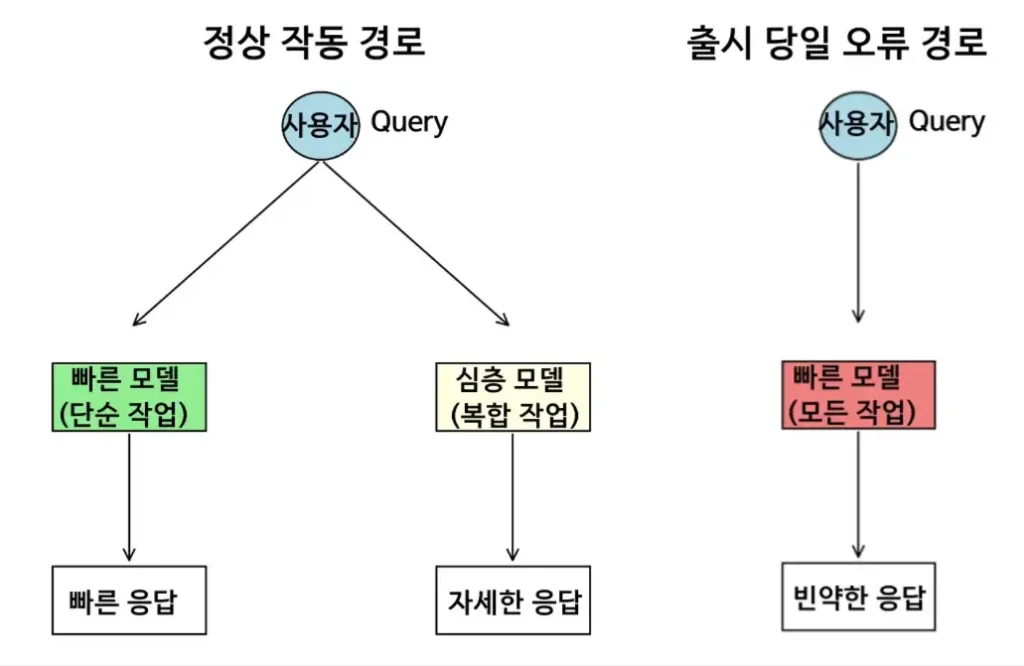
GPT-5의 핵심 기능 중 하나는 ‘오토스위처(autoswitcher)’였습니다. 이는 프롬프트의 난이도에 따라 두 가지 하위 모델 중 하나를 자동으로 선택하는 지능형 라우팅 시스템입니다. 간단한 질문에는 더 가볍고 빠른 모델을, 복잡한 질문에는 느리지만 분석력이 높은 모델을 선택해 응답을 생성하는 방식입니다. 이를 통해 사용자는 모드를 직접 바꾸지 않아도 GPT-5 성능을 극대화할 수 있도록 설계되었습니다.
출시 당일 발생한 문제
그러나 출시 당일, 오토스위처는 단순히 오작동한 것이 아니라 몇 시간 동안 완전히 멈춰버렸습니다. 모든 요청이 단일, 덜 강력한 하위 모델로만 전달되면서 GPT-5의 추론 능력이 눈에 띄게 약해졌습니다.
다단계 논리 문제, 코딩 작업, 심층 리서치 요청을 시도한 사용자들은 얕거나 불완전한 답변을 받았고, 일부는 GPT-4o와의 비교에서 이전 모델이 더 나은 성과를 낸다고 주장했습니다.
커뮤니티 반응과 OpenAI의 해명
반응은 빠르고 거셌습니다. Reddit과 X에는 GPT-5가 “더 멍청해졌다”, “졸속 출시됐다”, “아직 준비가 안 됐다”는 글이 줄을 이었습니다.
샘 알트만은 AMA에서 이 장애가 심각(severe)한 사건이었다고 인정하며, 오토스위처의 실패가 성능 저하의 직접적인 원인이라고 설명했습니다. 그는 두 가지 해결책을 약속했습니다.
- 오토스위처를 복구하고 안정화해 두 가지 하위 모델이 의도대로 작동하도록 함
- 어떤 모델이 요청을 처리했는지 사용자에게 표시하는 투명성 기능 추가
인식에 미친 영향
첫인상은 매우 중요합니다. 오토스위처 장애는 많은 사람들에게 GPT-5와의 첫 경험을 ‘제한된 버전’으로 만들어버렸습니다. 이후 문제가 해결되었더라도, 초기에 받은 실망감은 쉽게 사라지지 않았습니다. 비평가들에게는 이것이 마케팅이 약속한 것과 실사용 GPT-5 성능 간의 불일치를 보여주는 또 하나의 증거가 되었고, OpenAI에는 단 한 번의 백엔드 오류가 수개월간의 엔지니어링 성과를 가릴 수 있다는 교훈을 남겼습니다.
3. 이용 제한, 접근 문제, 그리고 GPT-4o의 삭제
이용 제한에 대한 불만
기술적 문제 외에도, 많은 사용자들은 새 버전에서 예상보다 낮아진 사용량 제한(rate limit)에 놀랐습니다. 특히 더 빠르고 더 많은 작업량을 처리할 수 있는 권한을 얻기 위해 비용을 지불한 Plus 구독자들은 GPT-4나 GPT-4o를 사용할 때보다 훨씬 일찍 사용 한도에 도달했습니다. 연구 워크플로를 돌리거나, 코드 생성 작업을 하거나, 고객 지원 자동화를 운영하는 파워 유저들에게 이는 단순한 불편이 아니라 업무를 중단시키는 수준의 문제였습니다. 결과적으로, 업그레이드가 편의성을 높이기보다 오히려 제한을 늘렸다는 인식이 퍼졌고, 이는 GPT-5 성능에 대한 신뢰를 약화시켰습니다.
GPT-4o의 갑작스러운 삭제
아마도 가장 감정적인 반발은 GPT-4o의 갑작스러운 삭제에서 비롯되었습니다. GPT-4o는 따뜻한 대화 톤, 자연스러운 흐름, 미묘한 뉘앙스 처리로 높은 평가를 받아왔고, 충성도 높은 사용자층을 확보하고 있었습니다. 그러나 별다른 경고 없이 GPT-4o는 메인 ChatGPT 라인업에서 제외되었고, GPT-5가 그 자리를 대체했습니다. OpenAI는 전환이 매끄럽게 이뤄질 것으로 예상했지만, 특히 오토스위처 장애 이후 많은 사용자들은 GPT-5를 완전한 대체품으로 보지 않았습니다. 소셜 미디어에는 “RIP GPT-4o”라는 글이 넘쳐났고, 구모델이 더 똑똑하고 공감력 있는 답변을 준다는 비교 스크린샷이 잇따랐습니다.
OpenAI의 대응
샘 올트먼은 AMA에서 OpenAI가 GPT-4o의 개성과 스타일에 사용자가 얼마나 애착을 가졌는지를 과소평가했다고 인정했습니다. 그는 두 가지 약속을 했습니다.
- Plus 구독자의 사용량 제한 두 배 상향
- GPT-5와 함께 선택 가능한 모델로 GPT-4o를 복귀시키는 방안 검토
이러한 조치는 불만을 잠재우고, 사용자 피드백이 실제로 제품 로드맵에 영향을 미칠 수 있다는 메시지를 전달하기 위한 것이었습니다.
출시 평판에 미친 영향
더 낮아진 접근 한도와 애정받던 모델의 삭제는 불만의 완벽한 폭풍을 만들어냈습니다. 수정이 이루어졌음에도 불구하고, 이야기는 기술적 개선보다 “이 시스템이 과연 사용자에게 더 나은가”라는 의문으로 흐름이 바뀌었습니다. 일부에게 이번 사건은 벤치마크 수치가 아닌, 신뢰와 선택권, 그리고 예기치 않은 변화 없이 안정적으로 도구를 사용할 수 있는 능력이야말로 실사용 GPT-5 성능을 정의한다고 다시금 상기시켰습니다
4. 커뮤니티 분위기와 인식 격차
출시 이후의 분위기
GPT-5 출시 첫 주가 끝날 무렵, 사용자 커뮤니티의 분위기는 기대에서 회의로 급격히 변했습니다. 차세대 모델에 대한 초기의 열광은 불만, 밈(meme), 그리고 “기업 베이지 좀비(corporate beige zombie)” 같은 조롱 섞인 별명으로 바뀌었습니다. 많은 사용자들에게 GPT-5가 쓸 수 없을 정도로 나쁘진 않았지만, 약속된 도약을 느끼기에는 부족했습니다. 기대와 실제 경험 사이의 이 간극이 빠르게 핵심 논점이 되었습니다.
벤치마크와 실제 사용의 차이
문서상으로 GPT-5는 뛰어난 성적을 거두었습니다. 공식 벤치마크에서는 추론 정확도, 코드 생성, 다단계 작업 처리 능력에서 향상이 입증되었습니다. 하지만 수개월간 GPT-4o를 사용해온 일상 사용자들은 GPT-5에서 반응성이 떨어지거나, 창의성이 줄거나, 어딘가 거리감이 느껴지는 순간들을 목격했습니다. 이런 경험은 벤치마크 점수의 가치에 의문을 던졌고, GPT-5 성능이 실제 사용자 요구를 얼마나 반영하고 있는지에 대한 논쟁을 불러일으켰습니다.
개성과 ‘대화 분위기’의 중요성
Reddit 스레드와 블로그 글에서 반복적으로 등장한 주제는 개성의 상실이었습니다. GPT-4o는 미묘한 유머, 공감 어린 문장, 인간적인 대화 리듬으로 유명했습니다. 반면 GPT-5는 기술적으로 정확하더라도 더 경직되고 중립적인 인상을 주는 경우가 많았습니다. 사실 전달 이상의 가치를 기대하는 창작·협업 중심 사용자들에게 이 변화는 점수 몇 점의 향상보다 훨씬 중요한 ‘다운그레이드’였습니다.
인식 격차가 중요한 이유
측정 가능한 기술 발전과 체감되는 유용성 사이의 간극은 단순한 홍보 문제를 넘어섭니다. 사람들은 벤치마크와 상호작용하지 않습니다. 그들은 출력물, 말투, 반응 속도와 상호작용합니다. 이 부분이 조금이라도 나빠졌다고 느끼면, 실사용 GPT-5 성능에 대한 평가는 발전이 아니라 후퇴로 바뀝니다. OpenAI가 배운 점은, 깨진 차트나 중단된 오토스위처를 고치는 것보다 인식의 회복이 훨씬 어렵다는 것입니다.
5. OpenAI의 회복 전략과 교훈
즉각적인 피해 통제
출시 후 불과 며칠 만에, OpenAI는 부정적인 여론을 잠재우기 위해 빠르게 움직였습니다. 잘못된 차트는 24시간 안에 교체되었고, 오토스위처는 패치되었으며, Plus 구독자의 사용량 제한은 두 배로 늘어났습니다. 샘 알트만의 긴급 AMA는 실수를 인정하고 변화를 약속하는 공개적인 자리가 되었습니다. 이러한 신속한 대응은 부정적인 헤드라인 확산을 늦추는 데에는 성공했지만, 많은 사용자의 첫인상을 완전히 지우지는 못했습니다.
중기적인 조정
즉각적인 수정 외에도, OpenAI는 투명성을 높이기로 약속했습니다. 어떤 하위 모델이 요청을 처리하는지 더 명확하게 표시하고, 향후 업데이트에 대한 릴리스 노트를 상세히 제공하며, GPT-4o를 Plus 구독자 전용 옵션으로 다시 도입하는 방안을 검토했습니다. 또한 대화 톤과 개성에 대한 피드백을 반영해 GPT-5의 응답 스타일을 조정하기 시작했습니다. 이는 실사용 GPT-5 성능이 단순한 기술적 정확성 이상을 필요로 한다는 점을 인식했다는 신호였습니다.
더 큰 교훈
이번 출시가 OpenAI와 AI 업계 전체에 남긴 핵심 교훈은 두 가지였습니다.
- 벤치마크 점수와 내부 테스트는 실제 사용자 경험을 대체할 수 없다.
- 제품 변경, 특히 모델 제거는 충성도 높은 사용자층을 잃지 않도록 신중한 소통이 필요하다.
회복 전략은 단순한 버그 수정이 아니라 신뢰 회복이었고, 사용자 피드백이 실제로 제품 발전 방향에 영향을 줄 수 있음을 보여주는 과정이었습니다.
6. 결론 및 AI 업계에 미치는 영향
GPT-5의 현재 위치
GPT-5는 여러 지표에서 향상을 보여주었지만, 이번 출시는 실행과 인식이 얼마나 다를 수 있는지를 보여주는 사례로 기억될 것입니다. 기술적 결함, 커뮤니케이션 실수, 그리고 간과된 감성적 요소들이 맞물리면서 GPT-5 성능 평가는 기능보다는 사용자가 느낀 ‘체감’에 의해 좌우되었습니다.
OpenAI를 넘어서는 교훈
이번 일은 OpenAI에만 해당되지 않습니다. 경쟁이 치열한 AI 시장에서 모델은 단순히 정확성과 속도만으로 경쟁하지 않습니다. 신뢰, 말투, 그리고 사람들이 일하거나 창작하는 다양한 방식에 얼마나 잘 적응하는지가 중요합니다. 이러한 인간적인 요소를 무시하면, 기술적으로 우수한 제품조차 ‘다운그레이드’라는 평가를 받을 수 있습니다.
앞으로의 방향
OpenAI가 GPT-5를 지속적으로 개선하고 GPT-4o의 재도입을 검토하는 과정에서, 이번 어려운 출시를 적응의 이야기로 바꿀 기회가 있습니다. 벤치마크 성과와 일상 사용성을 연결하는 데 성공한다면, 실사용 GPT-5 성능에 대한 평가는 실망에서 회복으로 바뀔 수 있습니다. 그러나 현재로서는 GPT-5는 기술적 이정표이자, 첫인상을 올바르게 만드는 것이 얼마나 중요한지 보여주는 경고 사례로 남아 있습니다.
📚 참고한 자료 모음
- Business Insider (2025) – OpenAI fixes ‘unintentional chart crime’ after people pointed out something was off in the GPT-5 livestream
https://www.businessinsider.com/openai-made-mistakes-with-charts-in-its-gpt-5-demo-2025-8 - The Verge (2025) – OpenAI gets caught vibe graphing
https://www.theverge.com/news/756444/openai-gpt-5-vibe-graphing-chart-crime - TechCrunch (2025) – Sam Altman addresses bumpy GPT-5 rollout, bringing 4o back, and the ‘chart crime’
https://techcrunch.com/2025/08/08/sam-altman-addresses-bumpy-gpt-5-rollout-bringing-4o-back-and-the-chart-crime - TechRadar (2025) – ChatGPT users are not happy with GPT-5 launch as thousands take to Reddit claiming the new upgrade ‘is horrible’
https://www.techradar.com/ai-platforms-assistants/chatgpt/chatgpt-users-are-not-happy-with-gpt-5-launch-as-thousands-take-to-reddit-claiming-the-new-upgrade-is-horrible - Windows Central (2025) – Did Sam Altman oversell GPT-5? OpenAI faces backlash for ruining ChatGPT, turning it into a ‘corporate beige zombie’
https://www.windowscentral.com/artificial-intelligence/openai-chatgpt/did-sam-altman-oversell-gpt-5-openai-faces-backlash-for-ruining-chatgpt-turning-it-into-a-corporate-beige-zombie





