
Scaling Agentic AI Systems: Governance, Reliability, and Operating Discipline Beyond the Pilot Stage
This blog is part 4 of 4 in the series : “The AI Value Gap: Scaling Transformation and Agentic Innovation.“
Engineering the Bridge Between LLM Autonomy and ERP/CRM Systems of Record.
How do you move Agentic AI systems beyond “pilot purgatory” and into a state where they can safely modify live business state without constant human “babysitting”?
Agentic AI is moving from isolated pilots into real enterprise workflows. But a system that works in a demo does not automatically become dependable at scale.
In an enterprise environment, the question is no longer only whether the agent can complete a task. The deeper question is whether the organization can govern its authority, monitor its reliability, audit its actions, escalate exceptions, and connect its work to measurable business value.
Figure 1 shows why scaling agentic AI systems requires a control plane. Governance, reliability, operating discipline, observability, human escalation, and auditability are the layers that turn a promising AI pilot into a trustworthy enterprise-scale system.
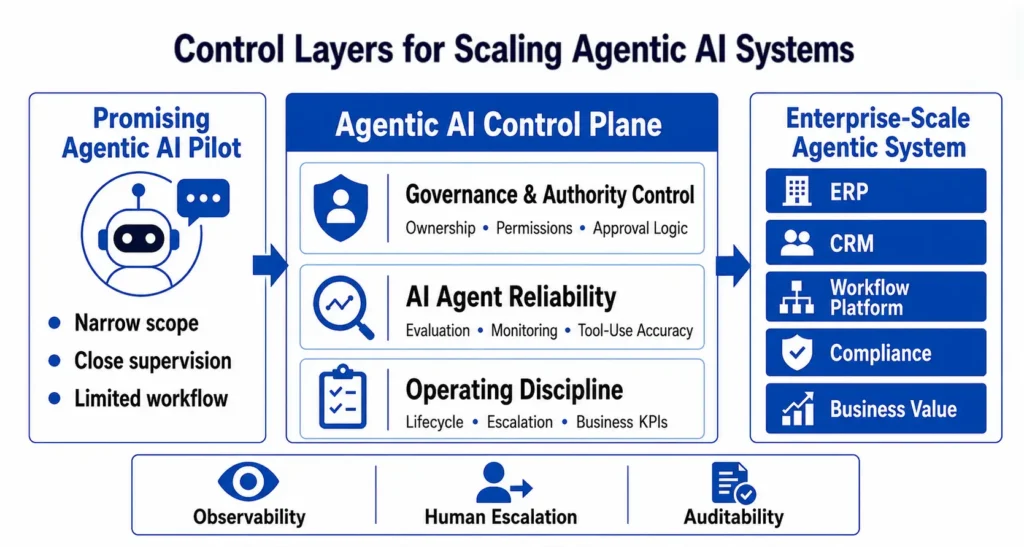
Scaling agentic AI systems requires moving from narrow, closely supervised pilots toward enterprise-scale systems supported by governance, reliability monitoring, operating discipline, observability, human escalation, and auditability. The agentic AI control plane provides the management layer that connects promising AI pilots to ERP, CRM, workflow platforms, compliance systems, and measurable business value.
1. Architectural Failure Modes: Why Agentic AI Systems Break in Production
The transition from a controlled sandbox to the live enterprise environment often exposes a harsh reality: many agentic AI projects struggle to reach durable production value. Gartner has predicted that over 40% of agentic AI projects may be scrapped by the end of 2027 because of rising costs, unclear business value, and immature implementation. For engineers, scaling Agentic AI systems requires moving beyond simple prompt-following and addressing the following critical failure modes:
- The Maintenance Trap and Logic Drift: Many systems work well in demos but “crash and burn” when handling actual business processes because they rely on static instructions. In production, business rules, SOPs, exceptions, and approval policies can change over time; without controlled updating, versioning, evaluation, and governance, agents can become difficult to maintain, requiring more human hours to “reprogram” than they save.
- Context Decay in Long-Running Workflows: A major concern for enterprises is whether AI agents remain stable, transparent, and trustworthy over time. High-level engineering must solve for “Context-Continuity,” the ability to maintain complex business logic and state over multi-day, multi-step processes without triggering a system-wide collapse or losing the objective mid-stream.
- The “Ugly Stepchild” Integration Gap: Many developers treat ERP applications as unwieldy legacy technology rather than core enablers. This leads to disconnected systems where an agent might process a CRM lead in seconds, but the organization still waits hours for a human to manually key that data into the ERP, effectively neutralizing productivity gains.
- Fragility of Visual-Based Automation: While breakthroughs like “Desktop Intelligence” allow agents to interact with legacy software by “seeing” the screen, this approach is inherently fragile. A simple UI update in the underlying ERP or CRM software can confuse the agent, making API-based “clean core” integrations far more reliable for background automation.
- The Coordination Theater of Siloed Agents: Failure often occurs when agents lack a modular, intelligent mesh that allows them to synchronize state across disparate platforms. Without a secure, governed bridge, agents remain “expensive advisors,” capable of analysis but fundamentally incapable of executing the meaningful system updates required in a production environment.
To solve these issues, architects are pivoting toward a hybrid approach that blends neuro-symbolic reasoning, where agents follow defined business rules (symbolic) while maintaining the flexibility to navigate edge cases through LLM intelligence (neural).
2. Governance as a Technical Control: Securing Agentic AI Systems
For the systems architect, governance is not a bureaucratic hurdle but a foundational technical constraint that dictates the system’s “blast radius.” When Agentic AI systems move from providing answers to executing transactions, the security model must shift from protecting data at rest to securing autonomous identities in motion.
- Non-Human Identity (NHI) Scoping: Every agent must be treated as a first-class non-human identity with its own verifiable credentials. By assigning unique service accounts or IAM roles rather than allowing agents to inherit broad user permissions, engineers can track, rotate, and revoke access without disrupting the broader ecosystem.
- The Least-Privilege Execution Model: Security scales when it follows cloud-native principles. Permissions should be attached only to the specific tools an agent needs, such as “write access to invoice table,” ensuring that even if the agent’s reasoning is influenced via prompt injection, it physically cannot access sensitive datasets or powerful administrative APIs.
- Tool Abstraction and Schema Enforcement: For production write actions, agents should avoid direct database access and operate through governed APIs, validated tools, or workflow services. Instead, they must operate through a tool abstraction layer that exposes discrete system actions via strict JSON schemas. This acts as a circuit breaker, validating that agent outputs are deterministic and type-safe before they are committed to the system of record.
- Auditability, Provenance, and Decision Reconstruction: For high-stakes workflows, agent actions should be logged, traceable, and reconstructable. Organizations should be able to show what data was used, what controls were applied, and how the decision produced an operational consequence. In regulated settings, this reconstructability may also support GDPR-style accountability, financial-control requirements, or sector-specific audit obligations.
- Hardwired Explainability: Governance teams must deploy multidisciplinary checks to ensure agent outputs align with organizational values. This involves building automated “guardrail” models that evaluate agent plans against ethical benchmarks and business-specific constraints before execution.
By treating governance as an integrated layer of the architecture, rather than a retrofit, developers ensure that Agentic AI systems are not only capable but also trustable and auditable in a production setting.
Figure 2 illustrates why agent permissions must be separated before an AI agent is allowed to move from recommendation into controlled execution.
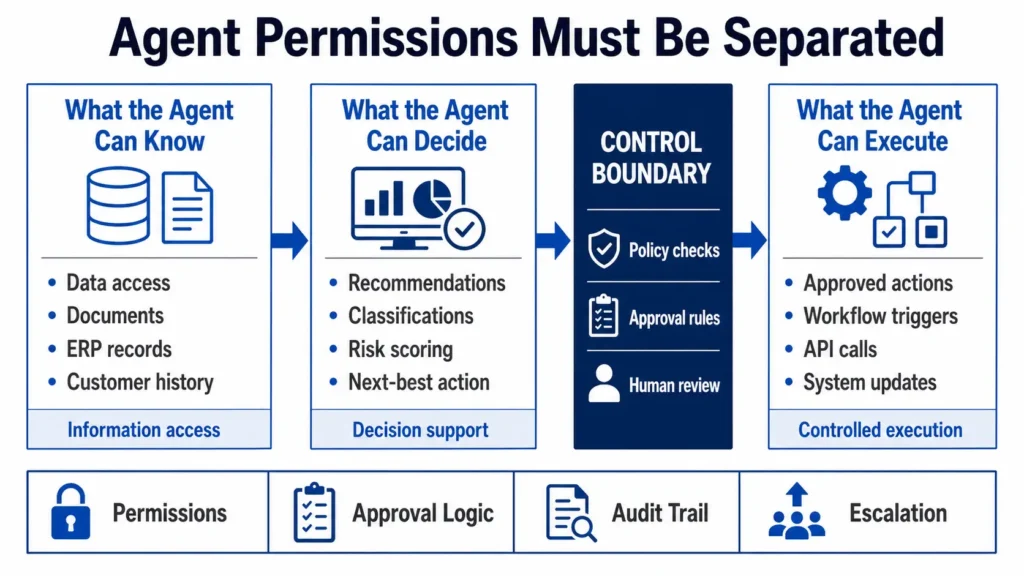
Governance separates what an AI agent can know, decide, and execute before it acts inside enterprise workflows. This separation is important because enterprise risk does not come only from what an agent says. It also comes from what the agent is allowed to access, recommend, approve, trigger, or change. By separating information access, decision support, and controlled execution, organizations can create clearer approval gates, audit trails, and escalation paths before agentic AI affects real business operations.
3. Reliability Engineering: From AI Agent Reliability to Enterprise Agentic AI Dependability
Reliability engineering for agentic AI should not stop at the agent level. An AI agent may produce correct outputs, use tools accurately, and complete tasks consistently, but enterprise-scale use requires a broader dependability structure around the agent.
In this article, AI agent reliability refers to task-level performance: output correctness, task consistency, tool-use accuracy, and failure-rate reduction. Enterprise AI dependability refers to the operating structure that allows that agent performance to become trustworthy inside real workflows.
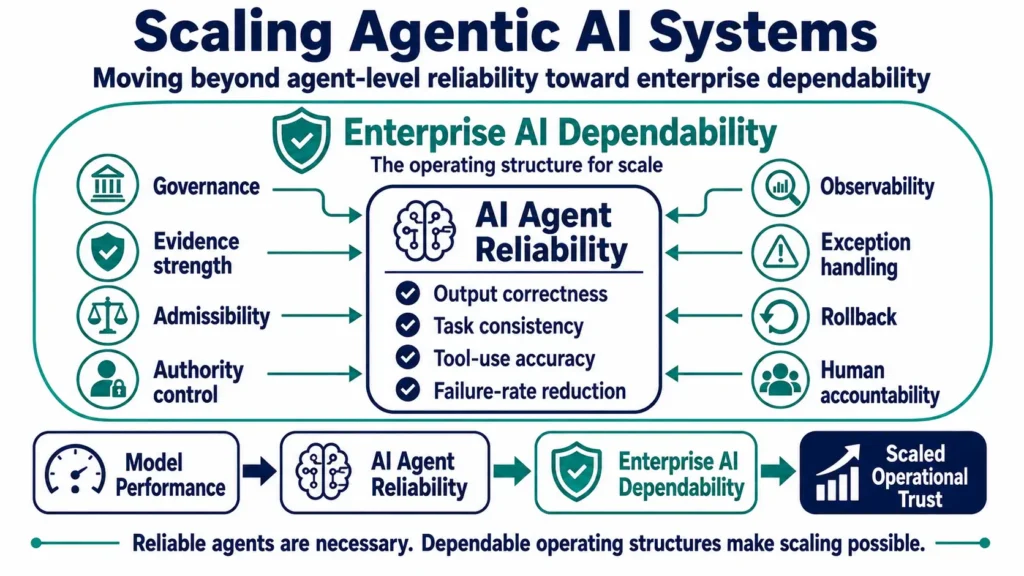
At enterprise scale, the reliability question changes. It is no longer only, “Did the agent complete the task correctly?” The deeper question is, “Can the organization keep this agent dependable as tools, permissions, workflows, data sources, models, and business rules change over time?”
This is where reliability engineering becomes broader than accuracy testing. It requires lifecycle evaluation, regression testing, monitoring, incident review, authority boundaries, rollback procedures, and operational feedback loops.
A useful way to think about this is through a Site Reliability Engineering (SRE) toolbox adapted for agentic AI systems:
- Service Level Objectives (SLOs): Define what reliable agent performance means in measurable terms, such as task completion accuracy, allowed failure rate, response latency, escalation rate, and successful tool-use rate.
- Error budgets: Set a tolerance limit for agent failures before expansion, automation, or additional tool access is paused.
- Incident review: Analyze agent failures, incorrect tool calls, unsafe recommendations, missed escalations, or workflow disruptions after they occur.
- Regression testing: Re-test agent behavior whenever prompts, tools, permissions, models, workflows, or business rules change.
- Monitoring and alerting: Track agent performance, tool-use patterns, exception frequency, policy violations, and drift signals in real time.
- Rollback procedures: Prepare a controlled way to reverse agent actions, disable risky workflows, or return authority to human operators.
- Human escalation paths: Define when the agent must stop, ask for approval, or transfer the case to a responsible human decision-maker.
For agentic AI systems, this SRE-style approach is especially important because the system is not static. Tools change, permissions expand, workflows evolve, data quality shifts, and business rules are updated. A system that was reliable during the pilot may become unreliable after new tool access, new workflow integration, or new operational authority is added.
In this sense, enterprise AI dependability is the operating discipline that connects agent-level reliability to trustworthy enterprise-scale execution. Without this dependability layer, organizations may have agents that look impressive in pilots but remain too risky for production workflows. With it, agentic AI systems can move from isolated task automation toward accountable, observable, and governable enterprise operations.
4. The Control Plane: Orchestration and Lifecycle of Agentic AI Systems
Once governance separates what an agent can access, decide, and execute, the next challenge is to manage those controls across the full lifecycle of the system. This is where the control plane becomes important.
The “control plane” of the enterprise serves as the centralized management layer where agentic AI systems are versioned, monitored, synchronized, escalated, audited, and improved over time. Its purpose is not only orchestration, but lifecycle dependability: keeping agentic systems trustworthy as workflows, data, permissions, models, and business rules change.
In this broader control-plane architecture, the “runtime governance layer” performs four execution-path functions: defining runtime controls, enforcing admissibility before action, notifying accountable owners when controls fire, and reconstructing decisions after execution.
- Standardizing Connectivity with MCP, the Model Context Protocol (MCP) acts as a universal “USB port,” provides a standardized way for AI applications to connect to external tools and data sources, reducing custom integration work.
- Context Persistence and Long-Term Memory, MCP can help agents access external context and tools, but long-term memory, workflow state, and business-rule persistence require separate state-management and governance layers.
- Multi-Agent Orchestration (MAO), enterprises are moving away from single-threaded automation toward “agent squads” where specialized agents collaborate on complex tasks and share real-time memory.
- The Enterprise Knowledge Graph, organizations are building structured maps of business logic, data relationships, and context to serve as the “cognitive backbone” for agent reasoning.
- Lifecycle Management Systems, these platforms act as “DevOps for AI workers,” supporting agent versioning, testing, and simulation to ensure continuous improvement without manual reprogramming.
- Outcome-Centric Monitoring, as orchestration matures, outcome-centric monitoring shifts attention from adoption metrics, such as user seats, toward business outcomes such as cases closed, cycle time reduced, or forecasts generated.
This architectural layer ensures that Agentic AI systems are not isolated scripts but integrated components of a broader, self-optimizing enterprise mesh.
5. Production Readiness: A Technical Checklist for Scaling Agentic AI Systems
Moving Agentic AI systems from a successful pilot to full-scale operations requires a final layer of technical validation to ensure that probabilistic reasoning can be converted into controlled, auditable, and policy-bound system updates. Engineers must verify that the following mechanisms are in place to manage the high-stakes environment of live ERP and CRM data:
- High-Fidelity Data Mapping and Validation, developers should utilize libraries like Pydantic or structured output mechanisms to enforce strict JSON schemas on agent responses, ensuring they align with the rigid requirements of ERP APIs.
- Intelligent Exception Handling and Routing, rather than allowing an agent to fail silently, the architecture must include logic to gather full state context and route “edge cases” to a human supervisor for final approval.
- Bounded Recovery Mechanisms, the system should recover automatically from low-risk, predefined operational failures, such as API timeouts or retryable data-entry anomalies. High-impact, uncertain, or irreversible failures should trigger alerting, escalation, rollback, or human review.
- Identity Scoping and Privilege Audits, every agent identity (NHI) must be audited to ensure it operates under the principle of least privilege, preventing unauthorized role assumption or full account compromise.
- Runtime Behavior Baselines, engineering teams should establish a behavioral baseline for each agent category, triggering alerts on deviations such as unusual API calls or unexpected network egress to external destinations.
- Compliance and Auditability Hardwiring, for regulated workflows, agent actions, approvals, inputs, outputs, and policy checks should be logged in a tamper-resistant audit trail appropriate to the applicable compliance regime.
- Lifecycle Reliability Review: Engineering and governance teams should define how the agentic AI system will be tested, monitored, updated, reviewed, escalated, and retired over time. This includes drift review, workflow change review, permission reassessment, rollback testing, authority review, and post-implementation evaluation.
6. Conclusion: Achieving Operational Excellence with Agentic AI Systems
The era of “babysitting” experimental AI is ending; the next stage of the enterprise is defined by Agentic AI systems that function as dynamic, self-directed software capabilities. For architects and engineers, this transformation is not just about choosing the smartest model, but about building the governed, reliable, and secure bridge between probabilistic AI and the deterministic core of the business. By shifting from feature-led development to capability-led design, organizations can finally move past “pilot purgatory” and compete on the speed and scale of autonomous value realization. Scaling successfully requires a new operating philosophy where trust is hardwired, outcomes are orchestrated, and enterprise agentic AI dependability is engineered as a lifecycle system property from deployment through continuous operation.





