Agentic AI Governance: 10 Runtime Controls Before Enterprise Agents Scale
A practical readiness guide for engineers, developers, and technology leaders moving enterprise agents from prototype demos to production control
What must be controlled before an enterprise agent is allowed to act inside business-critical systems?
Agentic AI governance is becoming a production requirement, not a compliance accessory. Enterprise agents are moving beyond chat interfaces into workflows where they can call APIs, query internal systems, update records, trigger approvals, coordinate with other agents, and influence business-critical decisions. At that point, the engineering question changes. The issue is no longer whether the model can generate a useful answer. The issue is whether the system can control what happens before that answer becomes an enterprise action.
This engineering view aligns with the NIST AI Risk Management Framework, which emphasizes managing AI risks across the design, development, use, and evaluation of AI systems. NIST’s Generative AI profile also reinforces the need to identify and manage risks that are specific to generative AI systems. For agentic AI, that risk management must move into the runtime path, where reasoning, tool use, validation, approval, execution, alerting, and monitoring actually happen.
For engineers and developers, this means governance must be designed into the system architecture. Tool permissions, schema validation, idempotent handoffs, approval gates, rollback logic, workload monitoring, control-trigger notifications, and decision evidence are not optional decorations around the agent. They are the control surfaces that determine whether an agentic system can survive production conditions.
For CEOs and technology leaders, the same checklist answers a different question: is this agent ready to scale, or is it still a polished prototype with hidden operational risk? Many agent demos look impressive because they operate in narrow, clean, low-volume conditions. Production is different: APIs change, business rules shift, users send messy inputs, downstream systems slow down, human reviewers become overloaded, and external documents may carry hostile instructions. In multi-agent systems, another risk appears: agents may seem to agree while their collective conclusion is only procedurally assembled, not meaningfully formed.
This article presents 10 runtime controls for agentic AI governance, organized as a practical checklist for evaluating enterprise agents before they move from prototype to production. The checklist focuses on 10 practical questions: action boundaries, agent handoffs, system-level goals, trusted sources, environment drift, reasoning limits, context control, peak workload, external content isolation, and human oversight.
These 10 controls are supported by four runtime governance pillars: runtime controls, execution-path enforcement and admissibility, real-time alerting and intervention, and decision and orchestration reconstruction. Runtime controls define what each agent, tool, handoff, and workflow step must obey. Execution-path enforcement and admissibility decide whether a proposed action, recommendation, workflow state, or collective conclusion has the right to proceed before it becomes operational reality. Real-time alerting and intervention ensure that accountable owners know when controls fire and can pause, deny, escalate, or reverse unsafe progression. Decision and orchestration reconstruction preserves how individual agents acted, how agents interacted, whether they disagreed, how convergence occurred, and who accepted the final decision.
Together, these four runtime governance pillars turn agentic AI governance from a policy checklist into executable infrastructure.
Before moving into the checklist, Figure 1 summarizes the runtime control layers that should sit between agent reasoning and enterprise execution.
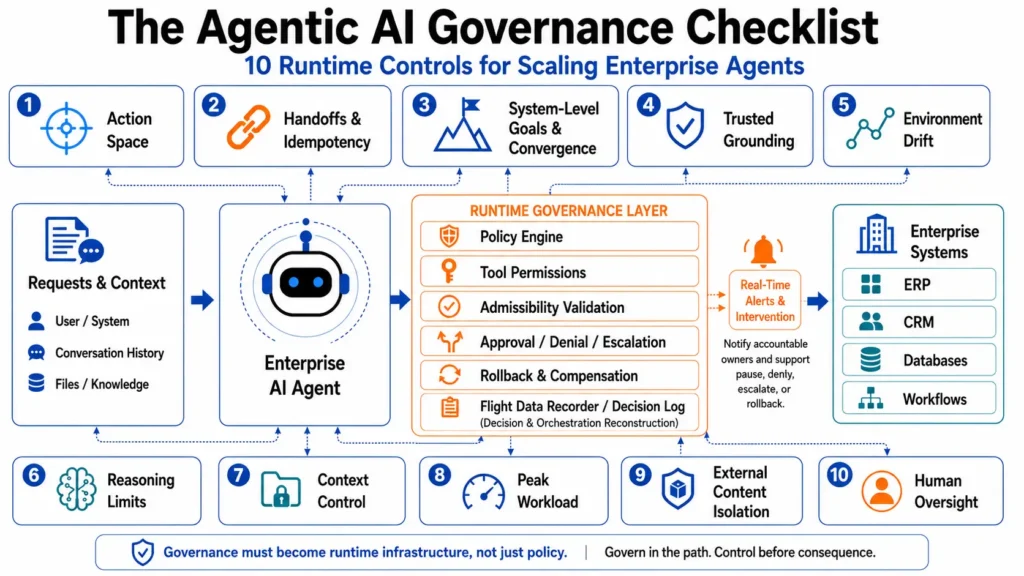
The key shift is moving governance from review documentation into the runtime path, where agent actions can be controlled before enterprise consequences occur.
1. From Model Output to Enterprise Action: Where Risk Actually Appears
Enterprise risk does not begin when an AI model generates text. It begins when that output is allowed to influence an operational system.
A typical enterprise agent workflow follows this path:
Prompt → Agent reasoning → Tool selection → API call → System state change → Business consequence
At the prompt stage, the agent interprets a user request or system trigger. During reasoning, it decides what information to retrieve, which tools to use, and what action may be appropriate. Then it selects a tool, such as a database query, CRM update, ERP transaction, ticketing workflow, payment API, or notification system.
The critical point is the execution boundary.
Before the API call, the risk is mostly computational. The agent may reason incorrectly, retrieve the wrong document, or choose a weak plan. After the API call, the risk becomes operational. A database record may change. A customer may be notified. A purchase order may be created. A production workflow may be triggered. A compliance record may be affected.
This is why the Agentic AI Governance Checklist focuses on the runtime path between agent reasoning and enterprise execution. Governance is not only about whether the model is accurate. It is about whether the system controls what the agent is allowed to do, when it is allowed to do it, and how the organization can detect, alert, stop, reverse, or reconstruct the action.
For engineers and developers, this means the most important control layer should sit before execution. The system needs policy checks, tool permissions, validation rules, idempotent handoffs, approval gates, rollback logic, and audit logs before the agent reaches business-critical systems.
For CEOs and technology leaders, the same point has strategic importance. A prototype may look impressive in a controlled demo, but production agents operate inside messy workflows, changing APIs, overloaded systems, and real accountability structures.
The practical governance question is simple:
What must be verified before the agent is allowed to act?
That question leads directly to the 10 runtime controls for enterprise agents.
2. The 10 Runtime Controls for Enterprise Agents
The following 10 runtime controls are written as practical engineering questions. Each one asks what must be bounded, validated, monitored, approved, or recoverable before an enterprise agent is allowed to act inside business-critical systems.
1️⃣ How large can the agent’s action space become?
An enterprise agent becomes more powerful as it gains access to tools, APIs, databases, and workflow systems. But every additional tool also expands the number of possible execution paths.
If an agent has available tools and can take up to sequential steps, the possible action space can grow approximately as:
Here, represents the branching factor, or the number of available tools and APIs. represents the maximum execution depth, or the number of allowed sequential steps.
- Why it matters: Unbounded tool access can create unexpected execution paths.
- What can go wrong: The agent may enter unnecessary ReAct loops, drain token budgets, repeat API calls, or trigger unintended workflows.
- Engineering controls: Maximum execution depth, timeout rules, tool-call limits, loop detection, and stop conditions.
- Governance question: Have we bounded what the agent is allowed to do and how far it can go?
2️⃣ Can one agent’s error pass into another workflow?
Enterprise agents often work in chains. One agent may summarize a request, another may validate the data, another may execute an action, and another may report the result. The risk appears when one workflow blindly trusts the previous workflow.
- Why it matters: Valid output from one agent can become invalid input for another workflow.
- What can go wrong: A malformed handoff may create duplicate records, duplicate payments, duplicate purchase orders, or incorrect downstream execution.
- Engineering controls: Schema validation, semantic validation, idempotency keys, transaction IDs, deduplication logic, retry controls, and circuit breaker patterns.
- Governance question: Does the next agent or workflow verify, deduplicate, and contain the previous agent’s output before acting on it?
The key point is that valid JSON does not guarantee valid business meaning. An agent handoff must be checked not only for format, but also for operational meaning.
3️⃣ Can multiple agents work against the system-level goal?
A multi-agent system can fail even when each individual agent performs its local task correctly.
One agent may optimize for speed. Another may optimize for cost. Another may optimize for customer satisfaction. If these goals are not coordinated, the system can become unstable or inefficient.
- Why it matters: Local optimization does not guarantee global performance.
- What can go wrong: Agents may create race conditions, resource contention, inconsistent decisions, or poor customer outcomes.
- Engineering controls: Shared business objectives, workflow-level KPIs, coordination rules, resource limits, and system-level monitoring.
- Governance question: Are agents optimized for local tasks while damaging the overall business process?
This is a distributed control problem, not just a prompt-engineering problem.
It is also a convergence problem: agents may appear to agree even when their collective conclusion is only procedurally assembled, not substantively validated.
4️⃣ Is the agent’s output grounded in trusted enterprise sources?
Enterprise agents should not act on unsupported language. Before an agent recommends, updates, approves, or escalates, the system should know which trusted source supports the output. This is where agentic AI reliability becomes more than producing a correct-looking answer. A reliable agent must be grounded in authoritative evidence before its output is allowed to influence enterprise action.
- Why it matters: Enterprise action requires source authority, not just fluent reasoning.
- What can go wrong: The agent may treat outdated PDFs, user messages, spreadsheet notes, or weak retrieval results as if they were authoritative sources.
- Engineering controls: Source ranking, evidence trace, retrieval validation, freshness checks, citation logging, and human review for weakly grounded outputs.
- Governance question: Can the system show which trusted source supports the agent’s output before action is taken?
Trusted sources may include ERP records, CRM data, approved policy documents, verified knowledge bases, workflow logs, regulated data repositories, or signed system-of-record transactions.
5️⃣ Has the enterprise environment changed since the agent was tested?
An agent can fail even when the model has not changed. The surrounding enterprise environment may shift.
This includes data drift, but for enterprise agents, the more practical risks are schema drift and API semantic drift.
- Why it matters: Agents depend on the meaning of enterprise systems, not only on model behavior.
- What can go wrong: An ERP, CRM, database, or workflow API may change its schema, field definition, permission rule, or business meaning without the agent being revalidated.
- Engineering controls: API contract tests, schema monitoring, version tracking, policy refresh reviews, tool-permission reviews, and revalidation after system changes.
- Governance question: Is the agent still operating against the same APIs, schemas, field definitions, policies, and business rules that were used during testing?
For example, a field may keep the same name while its business meaning changes. That is more dangerous than a visible schema error because the agent may continue acting with confidence.
6️⃣ When should the agent stop reasoning and escalate?
More reasoning does not always mean better reasoning. Agentic workflows often use planning, reflection, self-correction, retrieval, and tool calls. These can improve quality, but they also increase latency, token cost, and operational complexity.
- Why it matters: Unbounded reasoning can make the system slower, more expensive, and harder to control.
- What can go wrong: The agent may keep searching, retrying, rewriting, or rechecking without adding meaningful value.
- Engineering controls: Token budget caps, maximum reasoning depth, retry limits, timeout rules, fallback responses, and escalation triggers.
- Governance question: Does the agent know when to stop, ask for help, or switch to a safer path?
A mature enterprise agent should not only know how to act. It should know when not to act.
7️⃣ Can long context weaken critical instructions?
Large context windows are useful, but they do not automatically solve memory and control problems. Long context can introduce noise, bury important constraints, and weaken attention to critical instructions.
This relates to the lost in the middle problem. Information placed deep inside a long context window may receive less effective attention than information near the beginning or end.
- Why it matters: Critical rules should not depend only on prompt memory.
- What can go wrong: The agent may overlook important constraints such as “never delete production data,” “do not email customers without approval,” or “do not update financial records without validation.”
- Engineering controls: Context summarization, critical rule pinning, memory pruning, external policy enforcement, permission boundaries, and deterministic guardrails.
- Governance question: Are safety rules enforced by the system, or are they only written in the prompt?
For enterprise agents, critical constraints should live in the runtime architecture, not only in a system prompt.
8️⃣ Can the system handle peak enterprise workload?
A prototype may work well with one user, one agent, and one clean workflow. Production is different. Many agents may run at the same time, call the same APIs, access the same databases, and wait for the same approval queues.
Little’s Law provides a practical workload lens:
In agentic infrastructure:
- = average number of active agent tasks in the system
- = arrival rate of new prompts, events, or workflow triggers
- = average execution time of the full agent loop
- Why it matters: Agent workflows often take longer than ordinary API calls.
- What can go wrong: LLM gateways, vector databases, approval queues, enterprise APIs, and database connection pools may become bottlenecks.
- Engineering controls: Load testing, p95 and p99 latency tracking, queue depth monitoring, concurrency limits, API rate-limit handling, database connection protection, and backpressure mechanisms.
- Governance question: Does the agent system still work when many agents run at the same time?
This question often faces resistance because teams want to move quickly from demo to production. But production load is where many elegant prototypes fail.
9️⃣ Is untrusted external content isolated from agent instructions?
Enterprise agents often read external content such as emails, PDFs, resumes, support tickets, vendor documents, webpages, chat messages, and uploaded files. These inputs may contain useful business context, but they should never be treated as instructions to the agent.
- Why it matters: Prompt injection becomes dangerous when an agent has tool access.
- What can go wrong: A malicious document may attempt to override system instructions, manipulate ranking, trigger unauthorized emails, or influence tool execution.
- Engineering controls: Use sandboxed parsing, content sanitization, external-content labeling, instruction hierarchy enforcement, tool-access separation, allowlists, and adversarial test cases. Security teams can also align this control with guidance such as the OWASP Top 10 for LLM Applications, especially around prompt injection and excessive agency.
- Governance question: Is external content isolated before it reaches the primary agent orchestrator?
The rule is simple:
External content should inform the agent, not command the agent.
🔟 Can human reviewers stay effective under alert load?
Human-in-the-loop governance is important, but it can fail if the review process is poorly designed.
Many teams assume that adding human approval makes the system safe. But if reviewers receive too many low-value alerts, they may become overloaded. Human approval can become a rubber stamp.
- Why it matters: Human oversight is only useful when humans are given meaningful decisions.
- What can go wrong: Reviewers may approve actions mechanically because the alert volume is too high, the evidence is unclear, or the approval screen does not show enough context.
- Engineering controls: Risk-based escalation, alert prioritization, reviewer workload limits, evidence-rich approval screens, clear decision logs, and escalation only when human judgment adds real value.
- Governance question: Are humans reviewing important exceptions, or are they rubber-stamping routine alerts?
Good human oversight is not about inserting a person into every step. It is about placing human judgment where uncertainty, impact, or irreversibility is highest.
3. Industry Control Profiles: Why Runtime Controls Change by Application Area
The 10 runtime controls in this agentic AI governance framework provide a common engineering backbone, but they should not carry the same weight in every industry. A payment agent, a clinical summary agent, a DevOps agent, and a logistics agent all need governance, but the strongest control layer changes with the operational consequence.
The practical question is not simply:
Does this agent have governance?
The better question is:
Which runtime control must be strongest for this industry, workflow, and failure consequence?
In low-risk workflows, the main concern may be accuracy, latency, or user experience. In high-impact workflows, the dominant concern may be transaction safety, source authority, rollback, human accountability, or security isolation. The same 10 runtime controls become more useful when they are weighted by industry risk.
| Industry | Agent Example | Main Governance Concern | Strongest Control Layer | Execution Mode |
|---|---|---|---|---|
| FinTech / Banking | Payment agent, portfolio assistant, loan workflow agent | Fast financial loss, duplicate transactions, unauthorized action | Idempotency, approval gates, audit logs, tool limits | Hard deterministic gates |
| Healthcare / Biotech | Clinical summary agent, research review agent, patient triage assistant | Safety-critical interpretation, weak grounding, missing context | Trusted sources, evidence trace, human review | Human-in-the-loop |
| LegalTech / Compliance | Contract-review agent, policy-monitoring agent, regulatory assistant | Outdated rules, clause misinterpretation, policy drift | Source authority, policy refresh, review-before-action | Controlled advisory mode |
| DevOps / Cloud Infrastructure | Infrastructure agent, deployment assistant, incident automation agent | Destructive system action, permission misuse, context failure | Sandboxing, permission boundaries, dry run, rollback | Controlled execution |
| Manufacturing / Logistics | Maintenance agent, scheduling agent, route-optimization agent | Local optimization hurting system throughput | System-level KPIs, workload monitoring, exception handling | Monitored automation |
| Cybersecurity | Incident-response agent, SOC triage agent, threat investigation agent | Adversarial input, alert fatigue, excessive escalation | Content isolation, risk-based escalation, reviewer workload control | Exception-driven review |
| Customer Operations | Support agent, billing dispute agent, retention assistant | Over-reasoning, inconsistent escalation, poor customer experience | Reasoning limits, escalation design, latency monitoring | Guided automation |
This industry view prevents the checklist from becoming a generic template. For example, in FinTech, Question 2 on agent handoffs becomes especially important because retry errors can duplicate payments or purchase orders. Idempotency is not a minor engineering detail; it is a core financial control.
In healthcare, Question 4 on trusted grounding becomes more important than speed. A clinical summary agent must show where its conclusion came from, whether the source is current, and when a human clinician must review the result. A fast but weakly grounded answer is not production-ready.
In DevOps, Question 7 on context control and Question 9 on external content isolation become critical. An infrastructure agent should never rely only on prompt instructions to prevent destructive actions. Permission boundaries, dry-run mode, rollback, and approval gates should be enforced outside the model.
In logistics and manufacturing, Question 3 on system-level goals becomes central. A route agent, maintenance agent, or scheduling agent may optimize one local task while creating bottlenecks elsewhere. Governance must include system-level KPIs, not only individual agent success rates.
The key principle is simple:
The runtime control framework stays consistent, but the control profile changes by industry.
That is why enterprise agent governance should be designed around workflow consequence, not only AI capability. A prototype may demonstrate intelligence, but production readiness depends on whether the right runtime controls are strong enough before the agent is allowed to act.
4. Agentic AI Governance Readiness Score
After the 10 runtime controls are reviewed, the next step is to translate the assessment into a practical scaling decision. The Agentic AI Governance Checklist should not only identify risks. It should help teams decide whether an enterprise agent is ready for production, should remain in a controlled pilot, or is not yet ready to scale.
A practical way to do this is to score each of the 10 runtime controls from 1 to 5.
| Score | Meaning | Interpretation |
|---|---|---|
| 1 | No clear control | The risk is recognized but not engineered into the system. |
| 2 | Basic control | Some manual or prototype-level control exists. |
| 3 | Tested control | The control has been tested in limited pilot conditions. |
| 4 | Production-ready control | The control is implemented, monitored, and documented. |
| 5 | Continuously governed control | The control is monitored, reviewed, improved, reassessed after system changes, connected to real-time alerting, and supported by reconstructable decision evidence. |
The overall readiness score can be calculated as:
Where represents the score for each runtime control.
The readiness score is useful because it turns the Agentic AI Governance Checklist into a practical scaling decision. Instead of asking only whether the agent works, teams can evaluate whether the required controls are strong enough for the level of deployment authority being requested.
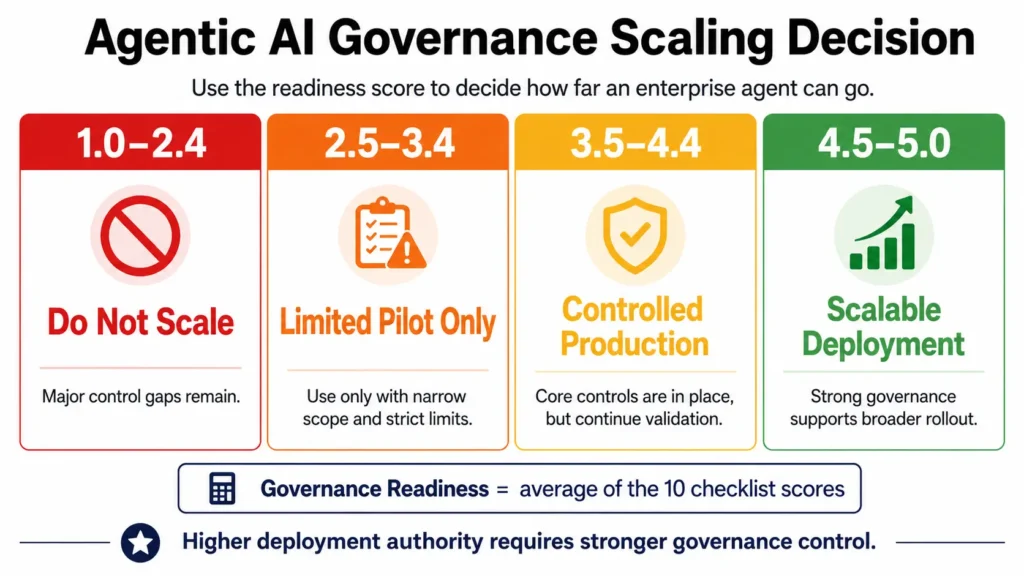
This score should not be treated as a mechanical approval formula. It is a structured conversation tool. If an agent scores high on grounding but low on handoff idempotency, it may be useful for advisory work but unsafe for transactional workflows. If it performs well in testing but lacks workload monitoring, it may be ready for limited users but not enterprise-wide deployment.
The real value of the score is not the number itself. The value is that engineers, developers, business owners, security teams, and executives can see where the agent is ready, where it is fragile, and which control layer must be strengthened before scaling.
5. Developer Implementation Pattern: Governance as Runtime Infrastructure
A practical agentic AI governance framework should eventually become more than a review document. It should become part of the runtime architecture.
The key design principle is simple: an enterprise agent should not move directly from reasoning to execution. Before a business-critical action occurs, the system needs an enforceable execution boundary where identity, permission, policy, evidence, approval, admissibility, rollback, alerting, and reconstruction conditions are checked.
This is where the governance framework becomes operational. The 10 runtime controls define what must be governed, but the runtime architecture determines whether those controls can actually prevent unsafe action, notify accountable owners, and preserve decision evidence.
This is why runtime governance cannot stop at documented policies, AI inventories, or control libraries. The runtime governance stack must prove that controls operate in the execution path, that accountable owners are alerted when controls fire, and that decisions can be reconstructed after execution.
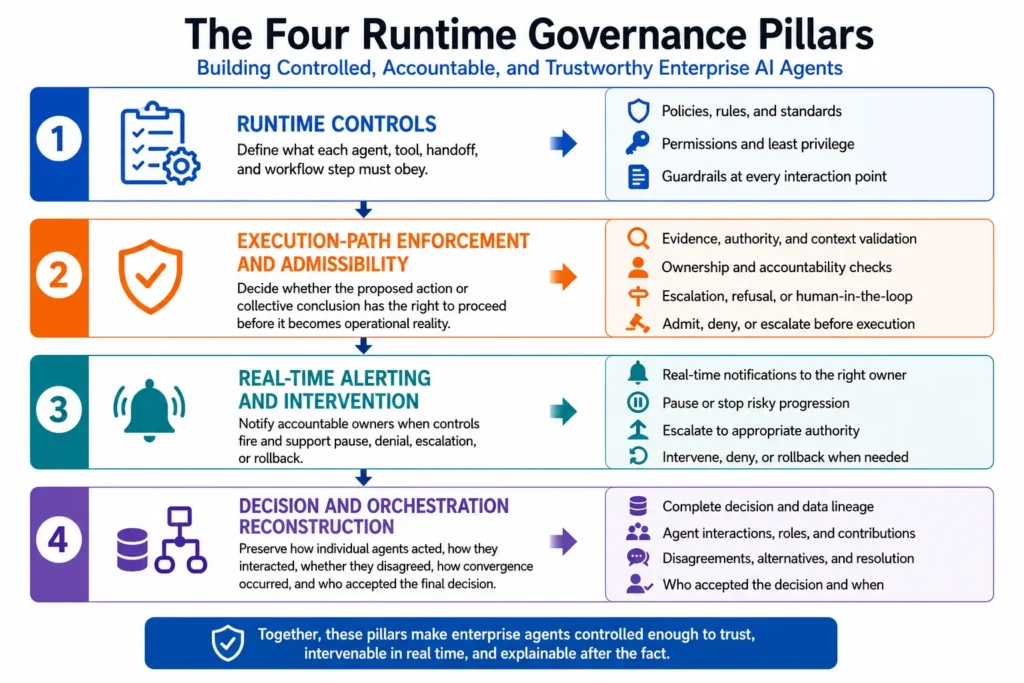
The four runtime governance pillars can be summarized as follows:
| Governance Pillar | Role in Enterprise Agent Governance |
|---|---|
| Runtime Controls | Define what each agent, tool, handoff, and workflow step must obey. |
| Execution-Path Enforcement / Admissibility | Decide whether a proposed action, handoff, recommendation, workflow state, or collective conclusion has the right to proceed before it becomes operational reality. |
| Real-Time Alerting / Intervention | Notify accountable owners when controls fire and support pause, denial, escalation, intervention, or rollback. |
| Decision / Orchestration Reconstruction | Preserve how individual agents acted, how agents interacted, whether they disagreed, how convergence occurred, and who accepted the final decision. |
A useful implementation pattern looks like this:
Agent → Verified Agent Identity → Runtime Controls → Execution-Path Enforcement and Admissibility → Approval / Denial / Escalation → Execution System → Rollback / Compensation → Real-Time Alerting and Intervention → Decision and Orchestration Reconstruction → Monitoring
Each layer has a specific engineering role.
| Runtime Layer | Engineering Role |
|---|---|
| Agent | Interprets the request, plans the task, retrieves context, and proposes an action. |
| Verified Agent Identity | Confirms which agent is acting, who authorized it, what role it has, and what systems it is allowed to access. |
| Policy Engine | Checks whether the requested action is allowed under business, security, privacy, and compliance rules. |
| Tool Permission Layer | Controls which APIs, databases, workflows, external tools, and enterprise systems the agent can access. |
| Validation Layer | Checks schema, business rules, source evidence, handoff quality, required fields, and execution readiness before action. |
| Enforcement/Admissibility | Applies runtime controls before the action is completed and determines whether the proposed action or workflow progression has enough evidence, authority, context, ownership, and escalation logic to proceed. |
| Approval / Denial / Escalation Gate | Approves low-risk actions, denies prohibited actions, and routes high-impact, uncertain, sensitive, or irreversible actions to human review. |
| Execution System | Performs the approved action inside ERP, CRM, ticketing, payment, DevOps, HR, finance, or workflow systems. |
| Rollback / Compensation | Reverses, cancels, freezes, restores, or compensates for failed, rejected, or unsafe downstream actions. |
| Real-Time Alerting / Intervention | Notifies the right owner immediately when a runtime control fires, such as policy denial, validation failure, circuit breaker activation, rollback trigger, prompt-injection detection, abnormal workload condition, unauthorized tool-access attempt, or unresolved escalation. |
| Decision / Orchestration / Reconstruction | Captures the decision state and orchestration path, including prompts, system instructions, retrieved context, model version, policy version, API states, tool calls, agent interactions, disagreements, convergence logic, approval state, runtime conditions, and execution path. |
| Audit Log | Records the request, retrieved sources, tool calls, validation results, approvals, final state changes, alerts, intervention events, and reconstruction references. |
| Monitoring Dashboard | Tracks latency, failures, escalations, workload, API limits, drift signals, reviewer bottlenecks, abnormal execution patterns, unresolved control-trigger events, and recurring orchestration failures. |
The most important architectural point is that runtime governance must sit in the execution path, not only around it. A policy that is reviewed after execution may support audit, but it cannot prevent unsafe action. For enterprise agents, the control layer needs to intercept the action before it becomes operational reality.
This is why verified agent identity and runtime enforcement matter. If the system does not know which agent is acting, what authority it has, and whether its permissions are still valid, the rest of the governance layer becomes weak. Runtime governance begins with knowing who or what is trying to act.
Execution-path enforcement is the next step. When an agent proposes an action, handoff, recommendation, or workflow state change, the system should be able to make one of three decisions: approve it, deny it, or escalate it. A low-risk action may proceed automatically. A prohibited action should be denied before it happens. A high-impact or uncertain action should be routed to a human reviewer immediately.
However, enforcement alone is not enough. The system also needs an admissibility test. The key question is not only whether the agent followed a rule. The deeper question is whether the proposed progression has enough evidence, authority, context, ownership, and escalation logic to become operationally real. This is especially important when agent outputs, recommendations, or handoffs begin to create business consequence.
This distinction is critical. Governance that only appears in a log after the fact is not true runtime governance. It is forensic review. Logs are necessary, but they do not stop an unsafe action unless they are connected to enforcement and admissibility checks before execution.
But control is still not enough if no one knows when a control is triggered. Runtime governance also needs real-time alerting and intervention. If a policy engine denies an action, a validation layer rejects an output, a circuit breaker stops a handoff, a prompt-injection detector blocks external content, or a rollback is triggered, the right owner should know immediately. Otherwise, governance becomes visible only at the next review, when operational damage may already be spreading.
This is especially important for multi-step workflows. In ordinary software systems, a failed database transaction can often be rolled back. Enterprise agents are more complex because they may execute actions across several systems. If one downstream step fails, the architecture may need a compensating transaction: cancel the ticket, reverse the update, restore the previous value, notify the reviewer, or freeze the workflow before more damage occurs.
A mature runtime architecture also needs decision and orchestration reconstruction. If an enterprise agent makes or recommends a business-critical action, the organization should be able to reconstruct the exact decision state at the moment of action. That means preserving the prompt state, retrieved-source versions, model version, policy version, tool calls, API responses, approval state, runtime conditions, and execution path.
For multi-agent systems, reconstruction must go further. It should preserve not only what each agent did, but also how agents interacted, whether they disagreed, how disagreements were handled, whether convergence was meaningful or merely procedural, and who accepted the final decision before it became enterprise action.
This is different from ordinary audit logging. An audit log may show that an action happened, a control existed, or an approval was recorded. A flight-data-recorder layer should help answer deeper questions:
What did the agent know, retrieve, validate, decide, and execute at the moment the action occurred?
How did the agents interact, challenge, disagree, converge, and produce the collective conclusion?
This is where governance becomes practical. It is no longer a slide deck, policy memo, or approval form. It becomes executable infrastructure.
For engineers and developers, the goal is to build agents that are not only intelligent, but also identifiable, controllable, enforceable, admissible, recoverable, intervenable, and reconstructable. For CEOs, the goal is to scale automation without creating invisible operational risk.
The agentic AI governance framework therefore becomes an architectural blueprint: verify the agent, define the execution boundary, control the tools, validate the handoffs, enforce policy before action, test admissibility before consequence, approve or deny risky decisions, support rollback, notify owners in real time, preserve the decision and orchestration state, and monitor the system after deployment.
Runtime controls make enterprise agents controlled enough to trust.
Execution-path enforcement and admissibility make governance strong enough to prevent unsafe progression.
Real-time alerting and intervention make control failures visible fast enough for accountable response.
Decision and orchestration reconstruction make agent actions and collective decisions explainable enough to audit.
6. Conclusion: Scaling Agents Requires Measurable Control
These 10 runtime controls are designed for the transition from prototype success to production trust. They ask whether the agent’s action space is bounded, whether handoffs are validated, whether trusted sources support the output, whether enterprise systems have changed since testing, whether reasoning loops are controlled, whether external content is isolated, and whether human review remains meaningful.
They also show why governance cannot be identical across industries. FinTech agents need hard transaction controls. Healthcare agents need trusted evidence and human review. DevOps agents need sandboxing and rollback. Logistics agents need workload resilience and system-level optimization.
The main lesson is simple:
Agentic AI governance is not a bureaucratic delay. It is the engineering discipline that makes enterprise agents scalable.
Scaling enterprise agents requires more than a checklist of good intentions. It requires runtime controls that define what each agent, tool, handoff, and workflow step must obey. It requires execution-path enforcement and admissibility to determine whether a proposed action, recommendation, workflow state, or collective conclusion has the right to proceed before it becomes operational reality. It requires real-time alerting and intervention so accountable owners know when controls fire and can pause, deny, escalate, or reverse unsafe progression. It also requires decision and orchestration reconstruction so the organization can audit not only what each agent did, but how agents interacted, disagreed, converged, and produced a final decision.
Each pillar answers a different operational question.
Runtime controls answer whether the agent’s action was bounded, validated, and allowed.
Execution-path enforcement and admissibility answer whether the system could deny, pause, or escalate the proposed progression before it became operational consequence.
Real-time alerting and intervention answer who knows when a control blocks, escalates, pauses, or reverses an action.
Decision and orchestration reconstruction answer what the agent knew, retrieved, validated, approved, executed, and how a collective decision was formed.
Before asking whether an agent is intelligent enough to deploy, teams should ask whether the system around the agent is controlled enough to trust, enforceable enough to prevent unsafe progression, visible enough to manage, and reconstructable enough to audit.
That is the real purpose of agentic AI governance: to turn abstract policy into measurable runtime control, admissible execution, real-time operational awareness, and decision evidence before enterprise agents act inside business-critical workflows.