Agentic AI Reliability: What NIST, OpenAI, and Google Say About Building Dependable Agents
Dependable agents need control layers, observability, guardrails, and accountable operating discipline.
If an AI agent can take real actions, who decides whether it is safe, reliable, and accountable enough to trust?
Agentic AI is moving quickly from demos and pilots into production workflows. As AI agents begin to use tools, access data, trigger actions, and support operational decisions, reliability can no longer mean only “the model gives a good answer.” It must also mean that the agent can operate safely, consistently, and accountably inside real workflows.
This is where the reliability challenge becomes more serious. If an AI agent can take real actions, organizations need to know whether its behavior is observable, testable, policy-aware, and recoverable. A reliable agent should not only complete a task. It should act within defined boundaries, leave evidence, escalate uncertainty, and allow human intervention when risk increases.
The problem is that reliability work is often compressed when product teams face pressure to ship. Evaluation, observability, guardrails, and operations may be treated as secondary controls rather than core production requirements. Figure 1 shows how this compression increases the risk of weak testing, low visibility, unsafe execution, and production incidents.
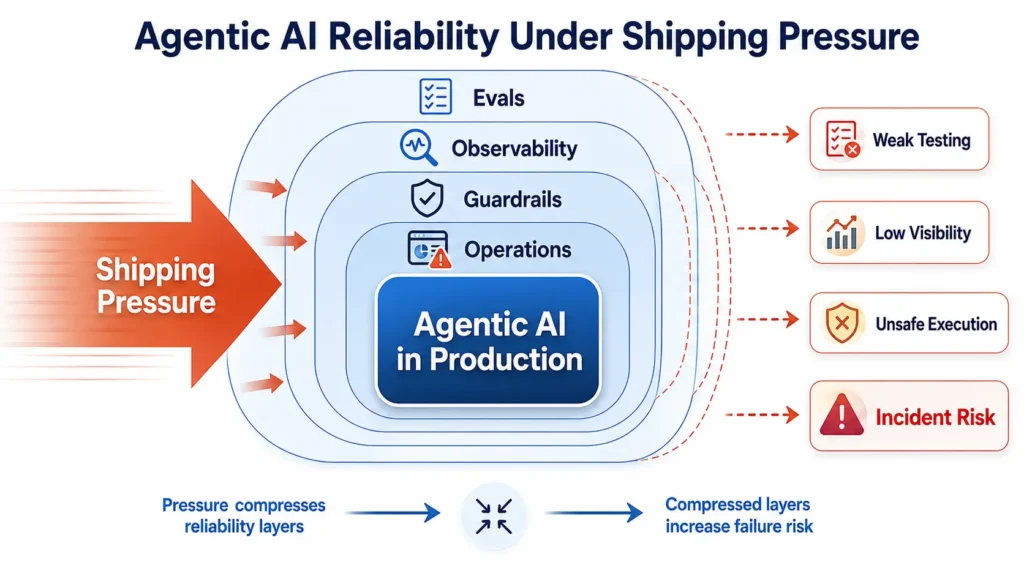
Shipping pressure does not always remove reliability controls directly. More often, it compresses them. Evaluation becomes lighter, observability becomes incomplete, guardrails become thinner, and operations are postponed until after deployment. That is how weak testing, low visibility, unsafe execution, and production incidents begin to appear.
1. Why Agentic AI Governance Still Breaks Down in Practice
Agentic AI governance does not usually break down because developers ignore risk. It breaks down because agentic systems create new failure patterns while delivery pressure pushes teams to release too quickly.
Traditional software usually follows predefined logic. AI agents are different. They can interpret goals, retrieve information, select tools, call APIs, coordinate with other agents, and act across multiple steps. That means the governance problem is no longer only about whether the code works or whether the model produces a useful answer. It is also about whether the system can control what the agent is allowed to do inside a real workflow.
Several practical reasons explain why agentic AI governance still breaks down in production:
Agentic systems behave probabilistically
The same or similar input may not always produce the same result. This makes testing, debugging, regression control, and approval logic harder.
Tool use expands the failure surface
An agent may query databases, call APIs, update records, or trigger workflows. Governance depends on whether it chooses the right tool, uses the right data, follows the right permissions, and stays within its authorized action space.
Multi-step workflows compound small errors
A small mistake early in the workflow can create a larger problem later. The agent may retrieve the wrong information, make a weak assumption, pass that assumption to another step, and then take action based on an error that has already compounded.
Multi-agent workflows create orchestration risk
In multi-agent systems, each agent may appear to complete its own role correctly, while the collective decision remains weak. Agents may converge procedurally without meaningful deliberation, independent evidence, disagreement handling, or clear ownership of the final decision.
Policy boundaries are easy to blur
A governed agent must know when to act, when not to act, when to ask for approval, when to escalate, and when to refuse. Without clear boundaries, the agent may complete the task but violate the process.
Admissibility is often checked too late
Many teams ask whether an agent output looks correct, but not whether the proposed action, handoff, recommendation, or workflow state has the right to proceed. In production, the key question is whether the progression has enough evidence, authority, context, ownership, and escalation logic before it becomes operational reality.
Failure definitions are often too weak
It is easy to ask, “Did the agent complete the task?” It is harder to ask, “Did it complete the task correctly, safely, within policy, with sufficient evidence, and with accountable ownership?”
Ownership is fragmented
Agentic AI governance often sits between model teams, application teams, security teams, data teams, compliance teams, and operations teams. When no one owns the full workflow, important risks can fall through the gaps.
Observability and alerting are added too late
Without traces, logs, metrics, workflow history, and real-time control-trigger notifications, teams may not know why the agent made a decision, what tool it used, where the failure began, or who should respond when a control fires.
Execution risk appears after deployment pressure increases
Many risks become visible only when the agent is connected to real systems. A chatbot that gives a weak answer may create inconvenience. An agent that updates a procurement record, changes an ERP field, sends a customer response, or triggers an internal workflow can create operational damage.
This is why agentic AI governance cannot be treated as a final checklist before deployment. It must be designed into the system from the beginning, across evaluation, tool-use boundaries, validation, approval, admissibility checks, real-time alerting, rollback logic, decision reconstruction, and operational review.
The better question is no longer:
“Does the agent work in a demo?”
It is:
“Can this agentic AI system behave dependably when it reasons, selects tools, coordinates with other agents, and acts inside a real enterprise workflow?”
2. What NIST, OpenAI, and Google Are Converging On About Agentic AI Reliability
NIST, OpenAI, and Google approach agentic AI reliability from different directions, but their messages increasingly point toward the same conclusion: reliable agents need evaluation, observability, guardrails, and operational controls before they can be trusted in real workflows.
NIST provides the risk-management frame. Its AI Risk Management Framework emphasizes governance, risk mapping, measurement, and management. For AI agents, this means teams should define risks early, assign ownership, measure failure modes, and manage reliability as part of the operating system around the agent.
OpenAI focuses more directly on agent workflows. Its guidance emphasizes evaluations, traces, guardrails, and observability. These controls help teams understand how an agent reasons, what tools it calls, where it fails, and when human review is needed.
Google points in the same direction for enterprise agents. Its approach emphasizes evaluating not only the final response, but also the agent’s trajectory, including tool use, intermediate steps, and workflow behavior.
The convergence is clear: dependable agents require more than isolated model performance. They need practical capabilities that make behavior testable, observable, constrained, recoverable, and governable.
Together, these sources point to a practical reliability stack for agentic AI systems:
• Evaluation
Teams need test sets, regression checks, edge-case scenarios, and workflow-level scorecards. The goal is to test not only the final answer, but also the path the agent followed.
• Observability
Teams need traces, logs, metrics, and dashboards that show what the agent did, what tools it used, what data it retrieved, and where the workflow changed direction.
• Guardrails
Agents need policy rules, permission limits, validation checks, and approval gates so they do not complete tasks in unsafe or unauthorized ways.
• Controlled execution
The more an agent can act, the more clearly its authority must be bounded. Triggering workflows, updating records, or changing operational states should stay inside defined approval and policy boundaries.
• Operational monitoring
Reliability does not end at launch. Agents need alerting, incident review, rollback plans, and continuous improvement as workflows, data, policies, and users change.
The important shift is this: reliable agents need more than model performance. They need a control architecture that makes behavior testable, observable, constrained, recoverable, and governable.
NIST gives the risk frame. OpenAI highlights agent workflow controls. Google emphasizes evaluation across responses and trajectories. Together, they point to one conclusion: dependable AI agents require a reliability architecture around the model.
3. The Four Agentic AI Reliability Layers Teams Actually Need
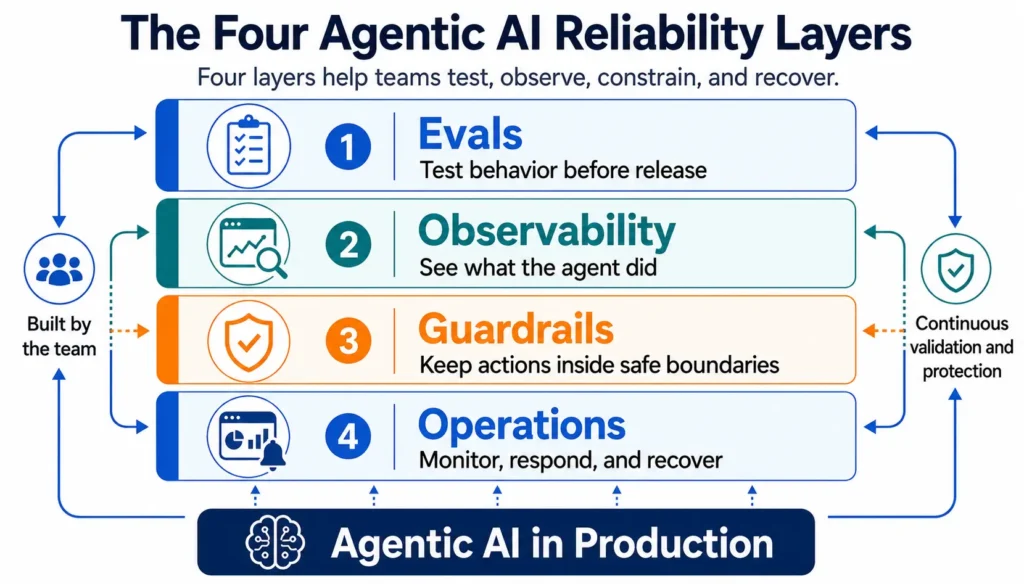
Agentic AI reliability becomes practical when teams translate broad principles into specific engineering layers. For production agents, four layers matter most: evaluations, observability, guardrails, and operations.
These layers are not optional add-ons. They are the basic reliability stack that allows teams to test agent behavior, monitor what happens inside workflows, constrain unsafe actions, and recover when failures occur.
Layer 1: Evaluations
Evaluations test whether the agent can perform its assigned function correctly across realistic scenarios. For agentic systems, this means testing not only the final answer, but also the path the agent takes to reach that answer.
A reliable agent should be evaluated for output correctness, tool-use accuracy, instruction following, policy compliance, and task consistency. Teams should also test edge cases, ambiguous requests, adversarial inputs, and workflow exceptions.
In traditional software, many failures can be tested through predefined logic. Agentic AI is different because the same task may produce different reasoning paths. That is why evaluations need to cover both single responses and multi-step trajectories.
Layer 2: Observability
Observability shows what the agent actually did inside the workflow. Without observability, teams may know that an outcome was wrong, but they may not know why it happened.
For agentic AI systems, observability should capture prompts, retrieved data, tool calls, intermediate steps, decision paths, approval events, failed actions, and handoff points. This makes agent behavior traceable instead of mysterious.
Observability is especially important when agents interact with enterprise systems. If an agent retrieves stale data, calls the wrong tool, skips an approval step, or triggers the wrong workflow, the organization needs evidence to understand what happened.
Layer 3: Guardrails
Guardrails keep the agent inside acceptable boundaries. They help prevent unsafe outputs, unauthorized actions, policy violations, and inappropriate tool use.
For simple AI applications, guardrails may focus mainly on content filtering. For agentic AI systems, guardrails must go further. They need to control what the agent can access, which tools it can call, what actions require approval, and when the agent must stop or escalate to a human.
This is where reliability begins to connect with execution control. A reliable agent is not only one that produces good answers. It is also one that respects operational boundaries.
Layer 4: Operations
Operations turn reliability into an ongoing discipline after deployment. Even well-tested agents can fail when data changes, permissions change, workflows change, or users interact with the system in unexpected ways.
Operational reliability requires monitoring, incident response, rollback procedures, escalation paths, and continuous improvement. Teams need to know when an agent is drifting, when failure rates are increasing, when tool calls are behaving unexpectedly, and when human review is required.
This layer matters because agentic AI reliability is not a one-time launch checklist. It is a production operating practice.
Why These Four Layers Matter Together
Each layer answers a different reliability question.
Evaluations ask whether the agent can perform the task correctly.
Observability asks whether the team can see what the agent did.
Guardrails ask whether the agent stayed within approved boundaries.
Operations ask whether the organization can respond, recover, and improve when failures occur.
Together, these four layers create the foundation for reliable agent behavior in production.
From Reliability Layers to Enterprise Dependability
These four layers improve AI agent reliability, but reliability alone does not make an enterprise AI system dependable.
AI agent reliability focuses on task-level performance, including output correctness, task consistency, tool-use accuracy, and failure-rate reduction. Enterprise AI dependability adds the operating structure needed to make that performance trustworthy at enterprise scale.
That broader structure includes governance, evidence strength, admissibility, authority control, exception handling, rollback, human accountability, and enterprise-wide observability.
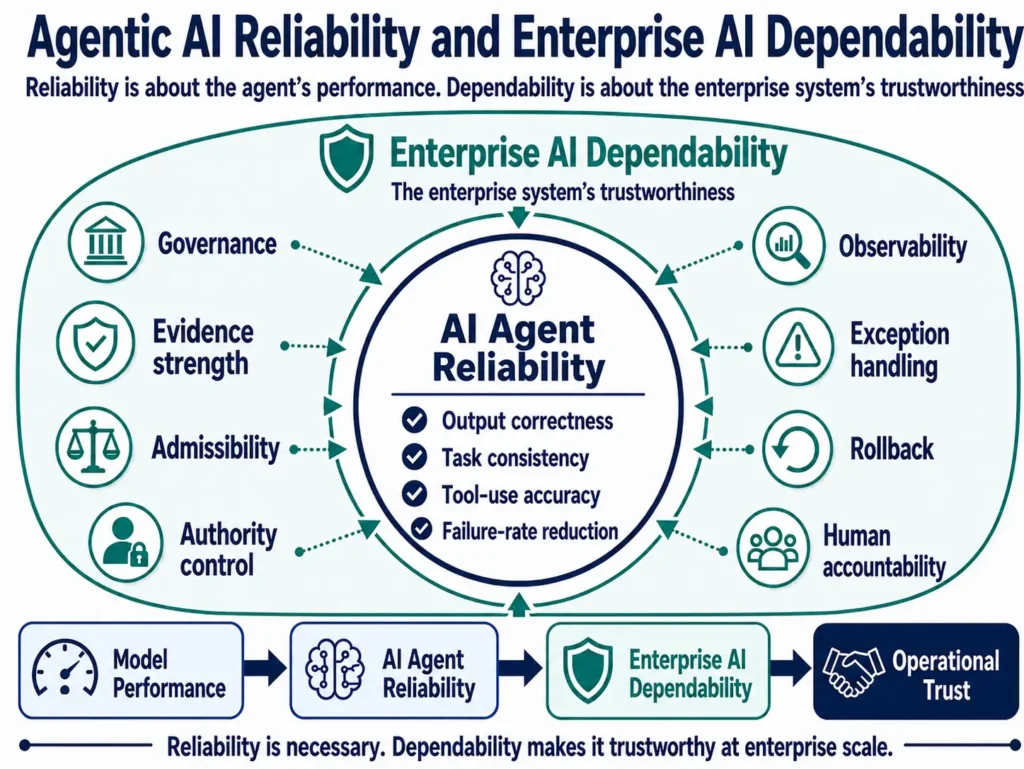
This distinction matters because production risk does not come only from what the agent says. It also comes from what the agent can access, what it can decide, which tools it can call, which workflows it can trigger, and who is accountable when something goes wrong.
In this sense, AI agent reliability is only the starting point. Enterprise adoption requires a broader dependability layer that connects governance, evidence strength, admissibility, authority control, observability, exception handling, rollback, and human accountability. Later in this article, these dependability requirements are translated into four runtime governance pillars: runtime controls, execution-path enforcement and admissibility, real-time alerting and intervention, and decision and orchestration reconstruction.
4. A Concrete Enterprise Failure Example: When Agentic AI Acts Without Control
Consider an AI agent assigned to support procurement operations. A manager asks the agent to review a supplier request and prepare an approval recommendation. The task sounds simple, but the workflow depends on several hidden control conditions.
The agent must retrieve the correct supplier record, check contract terms, compare pricing history, review budget limits, detect policy exceptions, and decide whether human approval is required. If any step is weak, the final recommendation may look reasonable but still be wrong.
The failure may begin quietly.
• Without evals, the team may never test enough procurement edge cases, such as expired contracts, duplicate vendors, unusual price increases, or approval thresholds.
• Without observability, no one may see that the agent used an outdated contract file or skipped a required pricing comparison.
• Without guardrails, the agent may recommend approval even though the request exceeds its authority or requires legal review.
• Without operations, the company may not have a clear alert, rollback, or incident process when the wrong recommendation reaches the procurement team.
This is where the ERP-Agent Bridge becomes important. AI agents need a trusted execution layer between agent reasoning and enterprise transactions. The bridge validates data sources, checks authority, applies approval rules, and creates an auditable path before recommendations become operational decisions.
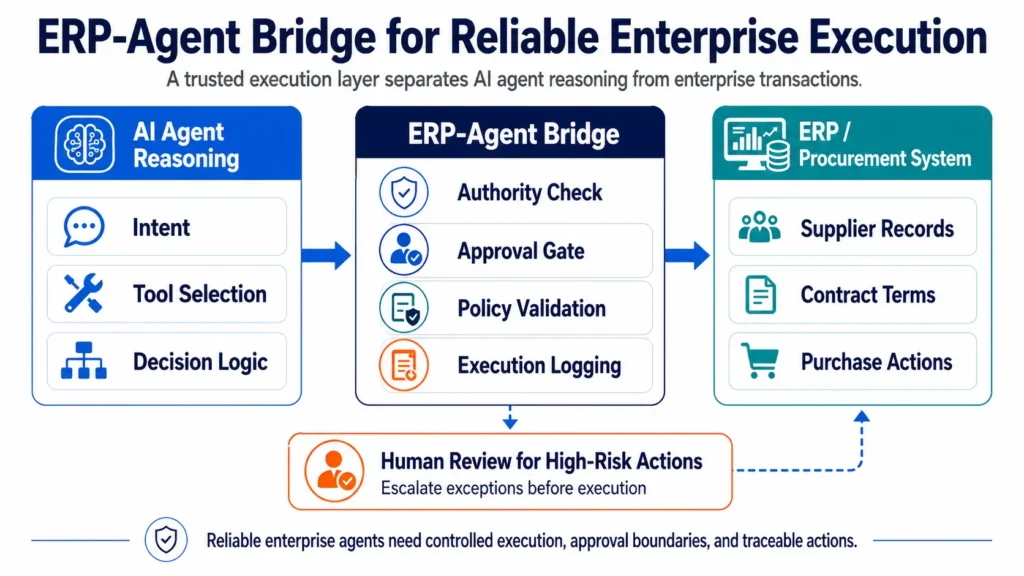
The ERP-Agent Bridge matters because enterprise risk begins at the boundary between recommendation and action. A procurement recommendation may look reasonable, but it should not influence approval, finance, compliance, or supplier operations until the system verifies the source of truth, confirms authority, applies policy rules, and records evidence for audit.
In this example, the problem is not that the model is useless. The problem is that the system around the model is too weak to verify, control, and recover from the agent’s actions.
That is why reliable AI agents still need a dependable enterprise operating system around them before they are trusted with real operational work.
5. From Agentic AI Reliability to Enterprise AI Dependability
Agentic AI reliability becomes an enterprise issue when agents move from answering questions to acting inside workflows. At that point, the concern is not only whether the agent can complete a task. The deeper concern is whether the surrounding system can verify, govern, interrupt, and recover from the agent’s behavior.
A reliable AI agent may perform its assigned function correctly. But enterprise AI dependability asks a larger question: can the entire operating system around the agent be trusted when it acts inside real workflows?
If the data source is outdated, the approval rule is unclear, or the tool permission is too broad, the agent may produce a confident decision that still creates risk. The problem is not only what the model knows. It is also what the system allows the agent to see, decide, and do.
This is why agentic AI reliability should be connected to, but not confused with, enterprise AI dependability. A dependable system does not assume every action will be correct. It is designed to prevent unsafe actions, detect weak signals, explain what happened, and recover when something fails.
For production agents, intelligence is only one layer. The larger question is whether the full system is measurable, visible, bounded, and recoverable.
That is the shift leaders need to understand. The future of reliable AI agents will not be decided only by model intelligence. It will be decided by the dependability architecture built around the agent.
6. What Developers, Engineers, and CEOs Should Do Next
AI agent reliability is not owned by one role. It requires different questions from different people.
Developers should instrument the workflow
Developers need to make agent behavior visible. That means tracing model calls, tool calls, retrieved data, intermediate decisions, failure states, and escalations. If an agent fails, the team should be able to answer what happened, where it happened, and why it happened.
Engineers should design for controlled execution
Engineers need to treat the agent as part of a larger production system. That means defining tool permissions, approval gates, rollback options, and monitoring rules. The goal is not only to make the agent useful, but to make its actions bounded and recoverable.
CEOs should ask deployment-level questions
CEOs do not need to inspect every technical detail, but they should ask the right reliability and dependability questions before deployment. What can this agent actually do? What systems can it access? What actions require human approval? How do we know when it fails? Who owns incident response?
The key point is simple: AI agent reliability is not a feature added at the end, and enterprise AI dependability is not owned by one team. Reliability is built through testing, tracing, guardrails, and controlled execution. Dependability is sustained through governance, operations, escalation, rollback, and accountable ownership.
7. Conclusion: Too Busy for Agentic AI Reliability Today Means Busy with Incidents Tomorrow
AI agents are moving from conversation to action. They can retrieve data, call tools, trigger workflows, and support real business decisions. That makes reliability more important, not less.
The lesson from NIST, OpenAI, and Google is clear: reliable AI agents require evaluations, observability, guardrails, and controlled execution. But enterprise AI dependability requires something broader: operational monitoring, governance, escalation, rollback, and accountable ownership.
Teams may feel too busy to build these layers today. But when an AI agent acts on the wrong data, skips an approval step, or triggers the wrong workflow, the time saved during deployment can quickly become time spent on incidents.
If teams are too busy for agentic AI reliability today, they may soon be busy with incident response tomorrow.