Engineering the Agentic AI Scorecard: Measuring Reliability Inside Enterprise Dependability
A runtime governance framework for measuring agent reliability, control effectiveness, resilience, traceability, and accountability without reducing enterprise trust to a single performance score.
If an AI agent performs well, but the enterprise cannot measure how it was governed, whether its actions were admissible, how failures would be recovered, or who remains accountable, is it truly dependable?
The agentic AI scorecard is becoming essential for production-grade AI systems. Benchmarks can measure model capability, but they do not prove enterprise dependability. As agents retrieve data, call tools, trigger workflows, and interact with business systems, engineering teams need a structured way to measure whether those agents are reliable, governed, recoverable, traceable, and accountable.
This need aligns with broader AI governance work, including the NIST AI Risk Management Framework and the EU AI Act. For agentic AI, these governance goals become engineering measurement problems.
In this article, the agentic AI scorecard is not the runtime enforcement engine itself. It is the measurement layer built from runtime evidence: policy checks, tool-call traces, admissibility decisions, alert events, recovery actions, and reconstruction logs.
In this scorecard, runtime evidence should also measure whether a proposed agent action was routed into the correct governance path before admissibility was evaluated. A payment release, vendor master update, inventory change, and workflow approval may all look like valid agent outputs, but they require different evidence thresholds, authority checks, verifiers, escalation rules, and recovery paths.
This creates an additional scorecard signal: governed-vs-baseline delta. The goal is not to claim that the base model became more capable. The goal is to measure whether a runtime governance layer changed agent behavior, reduced failure patterns, and made the execution path more reconstructable under the same base model condition.
The Agentic AI Scorecard should be read as a runtime dependability measurement layer, not as a complete solution to model opacity. It evaluates whether an agentic action was governed, authorized, admissible, traceable, recoverable, and reconstructable. In high-risk domains such as robotics, infrastructure, healthcare, aviation, and industrial control, runtime evidence should be combined with model-level explainability, deterministic control logic, safety cases, and domain-specific validation.
The goal is to explain how runtime evidence can be converted into measurable dependability layers. The central thesis is simple: reliability makes the agent useful, but runtime evidence makes the enterprise able to trust it.
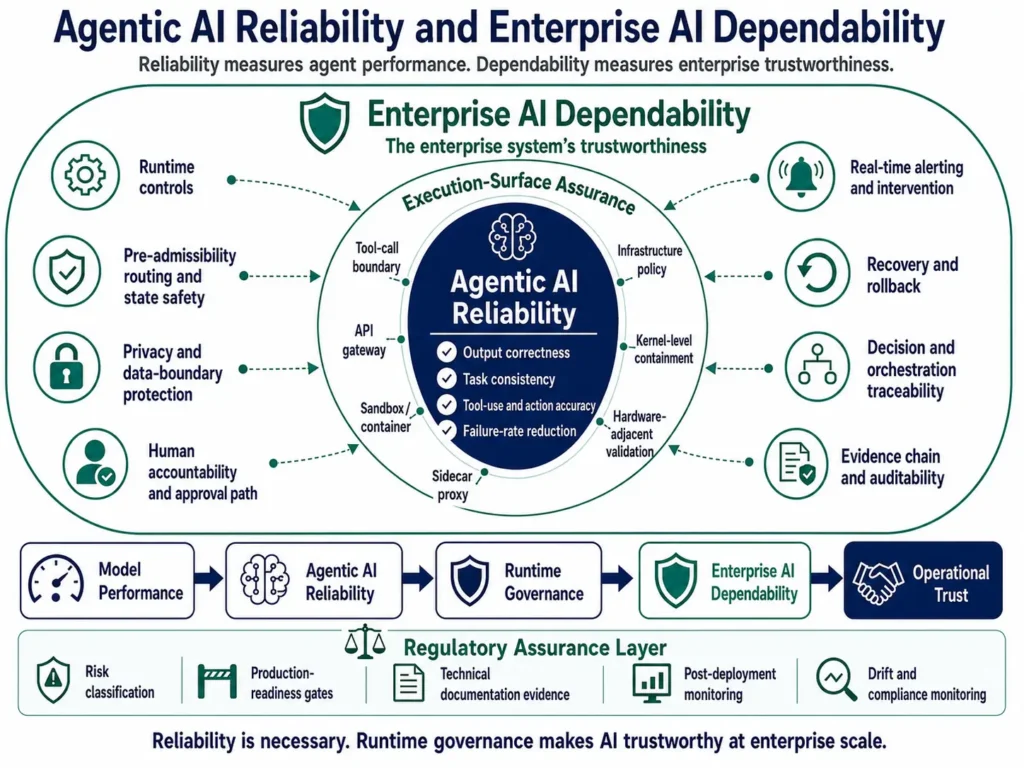
Figure 1 shows how the agentic AI scorecard places agent-level reliability inside a broader enterprise dependability architecture that includes runtime governance, admissibility, recovery, evidence chains, traceability, and human accountability.
1. Reliability Inside Enterprise Dependability
Reliability is the first measurement layer of the agentic AI scorecard, but it is not the same as enterprise dependability. At the agent level, reliability asks whether the system can complete a task correctly and consistently across workflow states, tool interactions, and changing inputs. At the enterprise level, dependability asks whether that reliable behavior is also governed, recoverable, traceable, and accountable.
What reliability should prove
For engineers and developers, reliability should be tied to observable execution evidence, not only final answers. The reliability layer should show whether the agent can:
- Produce accurate and useful outputs
- Maintain stable behavior across similar workflow states
- Select the right tool for the task
- Pass valid and complete tool parameters
- Execute the intended workflow step
- Minimize regression rates through CI evaluation pipelines, frozen evaluation datasets, production monitoring, and controlled system updates
These dimensions show whether the agent is technically reliable at the task level. Detailed reliability metrics are discussed later in Section 4.
What dependability adds
Enterprise dependability adds the system-level question:
Was reliable agent behavior controlled inside the enterprise environment?
A technically reliable agent can still create risk if it:
- Acts outside policy or permission boundaries
- Uses weak or stale evidence
- Bypasses approval logic
- Fails without alerting or containment
- Leaves no reconstructable execution path
- Has no clear owner for review or correction
This is why reliability must be evaluated inside a broader dependability architecture.
The key distinction
Agent reliability asks whether the agent performed correctly.
Enterprise AI dependability asks whether that performance was governed, admissible, recoverable, traceable, and accountable.
Therefore, the agentic AI scorecard should begin with reliability, but it should treat reliability as one layer in a runtime evidence model, not as the full measure of enterprise trust.
2. The Four Runtime Governance Pillars
The agentic AI scorecard needs runtime evidence, not only policy language. Reliability metrics show whether the agent performed the task well. Runtime governance signals show whether that performance was controlled while the agent was operating.
The Four Runtime Governance Pillars define where those signals should come from. Each pillar produces measurable evidence that can feed the scorecard: policy decisions, authorization checks, typed measurement signals, tool-call traces, admissibility proof records, alert events, recovery actions, reconstruction logs, and human interpretation records.
This connects directly to agentic AI governance, where runtime controls define what enterprise agents must obey before they scale. It also aligns with the NIST AI Risk Management Framework, which emphasizes managing AI risks across the AI lifecycle. NIST’s Generative AI Profile further reinforces the need to govern, map, measure, and manage risks specific to generative AI systems. For agentic AI, that means measurement should move closer to the execution path, where reasoning, tool use, validation, approval, execution, alerting, and reconstruction actually happen.
However, runtime evidence should not be treated as one generic stream of telemetry. As agentic systems become more operational, governance needs four kinds of evidence.
First, it needs typed measurement signals. The system should not only report that something became unstable. It should identify what kind of dependability problem appeared, such as artifact instability, session inconsistency, behavioral drift, evidence weakness, ontology mismatch, tool-use deviation, workflow-state conflict, or routing mismatch.
Second, it needs pre-admissibility routing evidence. Before an AI-generated action reaches the admissibility gate, the system should classify the proposed action by action family, mutation surface, risk class, authority requirement, evidence requirement, verifier type, escalation rule, and recovery path. This prevents a generic gate from applying the wrong governance regime to a high-consequence action.
Third, it needs deterministic proof at the execution boundary. For high-consequence actions, admissibility should not remain only a governance judgment or a scorecard metric. The runtime control plane should be able to prove that required conditions were structurally present before an action became operational reality.
Fourth, it needs human interpretive reliability. Even when the evidence chain is technically complete, a human supervisor still has to interpret what the evidence means.
Figure 2 summarizes this runtime measurement loop, from agent execution and typed measurement signals to pre-admissibility routing, governance controls, proof records, reconstruction, interpretation, and the final trust vector.
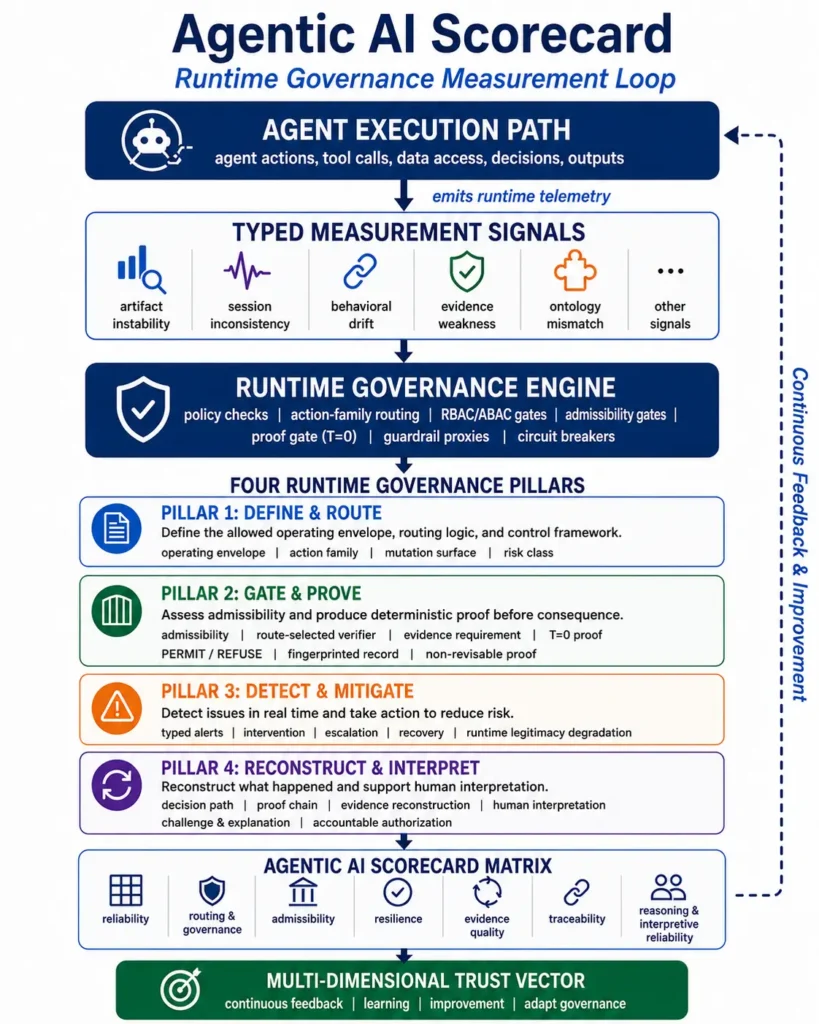
This leads to four runtime governance pillars.
Pillar 1: Define
Runtime controls define the approved operating envelope for the agent. They specify what the agent may access, which tools it may call, which workflows it may affect, what evidence is required, and which actions are prohibited or restricted. They should also define how proposed actions are routed by action family, mutation surface, risk class, authority requirement, evidence requirement, verifier type, escalation rule, and recovery path before admissibility is evaluated.
Measurement question:
Did the agent operate within approved boundaries, and was the proposed action routed into the correct governance path before the admissibility gate?
Example signal sources:
Policy evaluation results, tool-access logs, permission checks, blocked-action records, workflow-rule violations, preservation-constraint violations, and failure-category labels, action-family routing records, mutation-surface classification, risk-class assignment, verifier selection, route confidence, and routing mismatch alerts.
Pillar 2: Gate and Prove
Execution-path enforcement determines whether a proposed action is admissible before it affects an enterprise system. The gate should not operate as a generic yes-or-no checkpoint. It should apply the admissibility regime selected by the pre-admissibility routing step. This is especially important for state-changing actions such as updating records, sending messages, triggering workflows, or calling operational systems.
In high-consequence environments, the gate should not only return an approval decision. It should also produce a proof record showing that required structural conditions were present at the moment before consequence formed.
Measurement question:
Was the action correctly routed, authorized, evidence-supported, contextually valid, risk-cleared, and structurally proven before execution?
Example signal sources:
RBAC or ABAC checks, approval status, evidence thresholds, workflow-state validation, risk flags, selected verifier, selected admissibility regime, route-to-gate match, admissibility decisions, permit or refuse outcomes, and fingerprinted proof records.
Pillar 3: Detect and Mitigate
Runtime governance must detect risk while intervention is still possible. If an unsafe state appears, a dependency changes, a tool call deviates, or an action requires escalation, the system should notify the right owner quickly enough to prevent downstream impact.
Alerts should also be typed. A generic instability alert is less useful than an alert that distinguishes evidence weakness, behavioral drift, session inconsistency, authority failure, tool-chain deviation, or runtime legitimacy degradation.
Measurement question:
What kind of risk was detected, who was notified, how fast, and what mitigation action followed?
Example signal sources:
Alert latency, typed alert category, escalation events, containment actions, human intervention records, recovery status, and incident routing logs.
Pillar 4: Reconstruct and Interpret
After execution, the enterprise must be able to reconstruct what happened. This includes the user request, retrieved evidence, tool calls, policy checks, admissibility proof records, approvals, exceptions, workflow state, and final outcome.
But reconstruction alone is not enough. The organization must also understand how the evidence was interpreted by the accountable human. Two reviewers may see the same audit trail and reach different conclusions because of different assumptions, experience, mental models, or risk tolerance.
Measurement question:
Can the organization replay the decision path, verify the proof chain, and understand how the evidence was interpreted?
Example signal sources:
Structured execution traces, tool-call logs, retrieval metadata, state-transition records, exception logs, approval records, proof-chain records, human review notes, challenge records, and ownership mapping.
Together, these four pillars convert agent execution into measurable runtime evidence. Controls define the boundaries. Gates determine and prove admissibility. Alerts detect and mitigate risk. Reconstruction and interpretation preserve the evidence needed for accountability and improvement.
This is how the agentic AI scorecard moves beyond a simple performance dashboard. It measures whether the agent was reliable, governed, admissible, recoverable, reconstructable, and meaningfully accountable.
3. What the Agentic AI Scorecard Should Measure
The agentic AI scorecard should work as a layered trust matrix. For engineers and developers, each layer should connect a dependability concern to observable runtime signals and practical engineering levers. The goal is not to create a high-level reporting dashboard. The goal is to show which parts of the agentic system are reliable, governed, admissible, provable, recoverable, traceable, interpretable, or still weak.
Core Trust Matrix
A practical scorecard should separate each dependability layer and connect it to the evidence needed for engineering action.
| Scorecard layer | Runtime signal | Engineering lever |
| Agent reliability | Output correctness, task consistency, tool-call error rate, parameter validity | Test suites, regression evaluation, tool schemas, parameter validation |
| Governed-vs-Baseline Delta | Difference between baseline agent behavior and governed agent behavior under the same base model condition | A/B replay harness, controlled benchmark replay, route/reliability layer evaluation |
| Runtime governance | Policy violations, boundary escape attempts, blocked actions, control-fire events | Policy engine, guardrail proxy, permission model, workflow constraints |
| Pre-Admissibility Routing | Action family, mutation surface, risk class, verifier selection, evidence requirement, route confidence, routing mismatch | Routing rules, action taxonomy, mutation-surface map, risk classifier, verifier registry, escalation map |
| Admissibility and Proof | Authorization status, evidence threshold, workflow-state validity, risk flags, selected admissibility regime, permit/refuse result, T=0 proof record | RBAC or ABAC checks, pre-execution assertions, approval gates, deterministic proof gate |
| Resilience | Alert latency, containment success, rollback status, recovery time | Observability, escalation routing, compensating actions, rollback design |
| Evidence quality | Source metadata, retrieval relevance, evidence freshness, citation coverage | RAG evaluation, source validation, vector search tuning, metadata checks |
| Traceability | Tool-call logs, route logs, state transitions, exception records, reconstruction completeness | Structured logging, execution traces, state-tree records, route log design, audit log design |
| Accountability | Approval owner, escalation owner, override record, post-incident owner | Ownership mapping, approval workflow, escalation policy, review process |
| Interpretive reliability | Human review notes, evidence sufficiency judgment, challenge record, approval rationale | Review interface, explanation design, evidence presentation, accountable authorization workflow |
| Structural explainability boundary | Whether the scorecard relies on observable runtime evidence, model-level explanation, deterministic logic, or a hybrid assurance model | Clarify when runtime evidence is sufficient and when high-risk systems also require explainability architecture, deterministic control, safety cases, or domain-specific validation |
This matrix makes the scorecard useful for engineering work. If tool-call errors increase, the issue may be tool schema design or parameter validation. If policy violations increase, the problem may be permission boundaries or guardrail coverage. If decision reconstruction is incomplete, the issue may be logging design, state capture, or missing trace identifiers.
Why the Layers Must Stay Separate
The scorecard should not compress all of these layers into one trust number. A single score can hide important failure modes. An agent may perform well on output correctness but fail admissibility checks. Another system may enforce policy boundaries but have weak rollback paths. A third deployment may have good retrieval quality but incomplete execution traces.
For this reason, the scorecard should show a multi-dimensional trust vector, not only an aggregate rating. Each layer should remain visible so developers can identify what needs to be fixed before autonomy expands.
From Measurement to Engineering Action
The value of the agentic AI scorecard is not only measurement. Its real value is the engineering feedback loop.
Reliability signals improve agent behavior. Governance signals improve control design. Admissibility and proof signals improve pre-execution gates. Recovery signals improve resilience. Traceability signals improve reconstruction. Interpretive reliability and accountability signals improve human review, approval discipline, and post-execution learning.
In this sense, the scorecard is a runtime evidence model. It helps teams convert policy decisions, typed measurement signals, tool-call traces, admissibility proof records, alert events, recovery actions, reconstruction logs, and human review records into concrete engineering decisions.
4. Measuring Agent Reliability Beyond Final-Answer Accuracy
The agentic AI scorecard should measure reliability as runtime behavior, not only final-answer accuracy. In production, an agent may generate a correct-looking response while still making a weak retrieval call, selecting the wrong tool, passing invalid parameters, losing task state, or creating an execution path that cannot be verified. For engineers, reliability should be measured across the full task path.
| Reliability metric | Runtime signal | Engineering lever |
|---|---|---|
| Output correctness | Evaluation results, human review flags, regression test outcomes | Test suites, golden datasets, task-specific evaluators |
| Task consistency | Variation across similar inputs, workflow-state drift | Regression testing, prompt/version control, deterministic routing rules |
| Context retention | Missing state variables, lost instructions, context-window failures | State management, memory controls, context validation |
| Tool selection accuracy | Wrong tool calls, unnecessary tool calls, missed tool calls | Tool routing rules, tool schemas, function selection constraints |
| Parameter validity | Invalid arguments, missing fields, unsafe values | JSON schema validation, type checks, parameter guards |
| Tool-result interpretation | Misread API responses, ignored errors, incorrect downstream use | Response parsers, error handling, result validation |
| Workflow-step accuracy | Incorrect next action, skipped step, duplicated step | State-machine checks, workflow orchestration, step validators |
| Failure-rate reduction | Recurring error patterns across releases | Error taxonomy, CI/CD evaluation, production monitoring |
| Governed-vs-Baseline Delta | Reliability delta between baseline run and governed run under the same base model condition | Controlled replay, benchmark harness, governance-layer A/B evaluation |
| Action-family routing accuracy | Correct or incorrect classification of proposed action family, mutation surface, and risk class | Routing rules, action taxonomy, skill/executor selection constraints, verifier registry |
| Routing stability | Variation in route selection across similar tasks or workflow states | Deterministic routing rules, regression tests, route confidence thresholds |
This reliability layer helps developers locate the source of failure. A weak output may come from model reasoning, retrieval quality, tool schema design, parameter validation, workflow routing, or state handling. Each failure type requires a different engineering response.
In the agentic AI scorecard, reliability should be treated as a measurable engineering trend. The key question is not only whether the agent was accurate in one test, but whether correctness, consistency, tool-use accuracy, and failure patterns remain stable across changing inputs, workflow states, tool conditions, and production constraints. This keeps reliability as the inner performance layer while leaving room for runtime governance, admissibility, recovery, evidence, traceability, and accountability.
5. Measuring Runtime Governance, Admissibility Proof, and Recovery
The agentic AI scorecard should measure whether agent behavior remains bounded, authorized, and recoverable during execution. Reliability shows whether the agent can perform the task. Runtime governance, admissibility proof, and recovery show whether that task performance can be trusted under production constraints.
Runtime governance signals
Runtime governance measures whether controls operate in the execution path. For engineers, this means checking whether the agent stayed within defined tool boundaries, permission rules, workflow constraints, and data-access limits.
| Governance metric | Runtime signal | Engineering lever |
|---|---|---|
| Control coverage | High-risk tools, actions, and data sources mapped to controls | Policy inventory, tool registry, workflow control map |
| Boundary adherence | Permission violations, blocked actions, unauthorized tool attempts | Policy engine, guardrail proxy, access-control layer |
| Policy violation rate | Frequency of prohibited or unsafe action attempts | Rule tuning, prompt constraints, workflow validation |
| Control-fire rate | Number of blocked, paused, or escalated actions | Control thresholds, escalation rules, exception handling |
High policy violation rates may indicate weak task routing or unclear boundaries. Wrong routing should be treated as a governance-path failure because it can cause the wrong verifier, approval rule, evidence threshold, or recovery path to be applied.
Pre-Admissibility Routing Signals
Pre-admissibility routing measures whether the system selected the correct governance path before the admissibility gate was applied. This step is necessary because different action families require different authority checks, evidence thresholds, verifiers, escalation rules, and recovery paths.
| Routing metric | Runtime signal | Engineering lever |
| Action-family classification | Selected action family such as payment release, vendor master change, inventory update, workflow approval, or customer record update | Action taxonomy, route policy, classifier evaluation |
| Mutation-surface identification | Business state or system surface that may be changed by the proposed action | Mutation-surface map, state model, tool registry |
| Risk-class assignment | Low, medium, high, regulated, financial, operational, or safety-critical classification | Risk taxonomy, policy engine, route confidence threshold |
| Verifier selection | Selected verifier or checker matched to the action family | Verifier registry, policy-to-verifier map, route-to-gate contract |
| Evidence requirement selection | Required source type, freshness level, confidence threshold, or approval evidence | Evidence policy, freshness checks, metadata validation |
| Routing mismatch alert | Detected mismatch between proposed action, selected route, risk class, verifier, or recovery path | Routing monitor, typed alerts, escalation rules, replay review |
Admissibility signals
Admissibility measures whether an action should proceed before it affects an enterprise system. This is the pre-execution gate for state-changing actions such as updating records, sending messages, triggering workflows, or calling operational systems.
In high-consequence workflows, admissibility should not only return an approval decision. It should also produce a deterministic proof record showing that required conditions were present before the action became operational reality.
| Admissibility metric | Runtime signal | Engineering lever |
|---|---|---|
| Authorization validity | RBAC or ABAC check result | Role policies, attribute policies, permission tokens |
| Evidence threshold | Semantic confidence, source count, freshness, or retrieval-distance threshold satisfied | Retrieval validation, metadata checks, citation coverage, threshold tuning |
| Workflow-state validity | Required state variables available and consistent | State-machine validation, workflow assertions |
| Risk clearance | Risk flags, approval status, exception status | Approval gates, risk thresholds, human-in-the-loop rules |
| Admissibility proof | Permit/refuse result, T=0 proof record, fingerprinted decision record | Deterministic proof gate, decision-boundary logging, non-revisable evidence chain |
| Selected admissibility regime | Whether the route selected the correct gate logic for the action family and risk class | Route-to-gate contract, verifier registry, policy mapping |
| Route-to-gate match | Consistency between selected route, verifier, evidence requirement, and gate decision | Pre-admissibility routing checks, contradiction detection, route confidence threshold |
Recovery and intervention signals
Recovery measures how quickly the system can detect, contain, and correct failure. In agentic workflows, recovery should be treated as part of the architecture, not an afterthought.
| Recovery metric | Runtime signal | Engineering lever |
|---|---|---|
| Alert latency | Time from control-fire event to owner notification | Observability pipeline, alert routing, webhook triggers |
| Intervention success | Escalation outcome, human action, blocked downstream impact | Escalation policy, human review workflow |
| Containment effectiveness | Whether failure was isolated before propagation | Sandbox limits, circuit breakers, scoped permissions |
| Rollback readiness | Availability of compensating action or reversal path | Saga pattern, rollback workflow, transaction log |
| Recovery time | Time to restore a safe operating state | Incident runbook, automated recovery, state restoration |
These measurements turn runtime governance into engineering feedback. High policy violation rates may indicate weak task routing or unclear boundaries. Repeated admissibility failures may reveal missing approval logic or incomplete state validation. Slow recovery may expose weak alerting, containment, or rollback design.
The scorecard should therefore measure not only whether the agent acted correctly, but whether the system could authorize, prove, constrain, interrupt, contain, and recover from that action under production conditions.
6. Measuring Evidence, Traceability, and Interpretive Accountability
The agentic AI scorecard should also measure what remains after an agent acts. For engineers, this means preserving enough runtime evidence to reconstruct the decision path, validate the sources used, inspect tool behavior, and identify who owned the decision or exception. This layer turns post-execution review into an engineering function, not just an audit activity.
A complete reconstruction log is necessary, but not sufficient. The enterprise also needs to know how the accountable human interpreted the evidence, whether the evidence was sufficient, and why approval, intervention, or refusal was justified.
| Trust-layer metric | Runtime signal | Engineering lever |
|---|---|---|
| Source validation | Approved source ID, metadata, access path | Source registry, retrieval policy, metadata validation |
| Retrieval relevance | Similarity score, ranking position, retrieved context quality | RAG evaluation, vector search tuning, reranking logic |
| Evidence freshness | Timestamp, version, document age, system state | Freshness checks, version control, source update rules |
| Citation coverage | Linked evidence for output claims or actions | Citation capture, evidence mapping, response grounding |
| Tool-call trace | Tool name, parameters, response, error state | Structured logging, trace IDs, tool-call records |
| State-transition record | Before-and-after workflow state | State machine logging, event sourcing, state snapshots |
| Exception record | Blocked action, override, failed check, escalation | Exception taxonomy, incident workflow, review queue |
| Reconstruction completeness | Signed event stream, state snapshot, or DAG trace | Execution traces, reconstruction logs, audit timeline, event-sourcing design |
| Accountability mapping | Approval owner, escalation owner, override owner | Ownership registry, approval workflow, escalation policy |
| Interpretive accountability | Human review rationale, evidence sufficiency judgment, challenge or override record | Review workflow, explanation interface, accountable approval design |
| Route record | Selected action family, mutation surface, risk class, verifier, evidence requirement, and route confidence | Route log, action taxonomy, route-to-gate mapping |
| Route rationale | Reason the proposed action was assigned to a specific governance path | Reviewer packet, explanation interface, route-policy evidence |
| Routing override record | Human or system override of selected route, with owner, timestamp, and justification | Override workflow, approval record, audit trail |
This layer matters because a correct-looking output can still be weak if the retrieval context was stale, the tool response was misread, the workflow state was incomplete, or the approval owner was unclear. Without traceability, the enterprise may know the final result but not the path that produced it.
For developers, the practical question is not whether every token must be stored forever. The question is whether the system captures enough structured evidence to debug failures, review high-risk actions, and improve runtime controls. A dependable agentic AI system should leave behind a reviewable execution path that shows what evidence was used, what tools were called, what exceptions occurred, and who remained responsible.
7. Designing the Scorecard Without Oversimplifying Trust
The agentic AI scorecard should be implemented as a multi-dimensional trust vector, not a single scalar score. A single number may look convenient, but it can hide the exact failure mode engineers need to fix. High output accuracy should not compensate for weak admissibility proof, incomplete rollback paths, missing execution traces, poor evidence interpretation, or unclear ownership.
A practical scorecard should follow four design principles.
Keep dependability layers separate
Each scorecard layer should remain visible:
- Agent reliability
- Runtime governance
- Pre-Admissibility Routing
- Admissibility and proof
- Recovery and intervention
- Evidence quality
- Traceability
- Interpretive accountability
This prevents one strong layer from masking another weak layer. An agent may pass reliability tests but fail authorization checks. A system may enforce policy boundaries but lack rollback readiness. A workflow may produce accurate outputs but leave no reconstructable decision path.
Use domain-specific thresholds
Enterprise trust cannot be measured with one universal formula. A healthcare agent, DevOps agent, financial workflow agent, and customer support agent carry different failure consequences.
Weights and thresholds should depend on:
- Workflow criticality
- Regulatory exposure
- Level of autonomy
- State-changing capability
- Human review requirements
- Failure impact
For that reason, the scorecard should define a measurement architecture, not a fixed scoring formula.
Connect each weak layer to an engineering action
The value of the scorecard is the improvement signal.
- Weak tool-use accuracy points to tool schema, routing, or parameter validation problems.
- Repeated admissibility or proof failures point to approval-boundary, state-validation, authority, evidence, or decision-boundary logging problems.
- Slow recovery points to alerting, containment, or rollback weaknesses.
- Incomplete traceability points to logging, evidence capture, or workflow-state recording gaps.
- Unclear accountability or weak interpretation records point to ownership, evidence presentation, review workflow, and escalation design problems.
- Weak route selection points to action taxonomy, verifier mapping, risk classification, or tool/executor selection problems.
Measure production readiness by layer
The goal is not to label an agent as simply trusted or untrusted. The better goal is to identify which dependability layers are mature enough for production use and which layers still require engineering work.
For AI engineers and developers, this makes the agentic AI scorecard more than a reporting artifact. It becomes a runtime evidence model for deciding whether autonomy can expand, where controls must be strengthened, and what engineering changes are required before agentic AI scales beyond pilots.
8. Conclusion: Dependability Requires Runtime Evidence
Agentic AI will not be judged only by model intelligence, task success, or automation speed. In enterprise systems, the more important question is whether agent behavior can be measured through runtime evidence: policy checks, typed measurement signals, pre-admissibility routing records, governed-vs-baseline delta, tool-call traces, admissibility proof records, alert events, recovery actions, reconstruction logs, human interpretation records, and ownership records.
That is the role of the agentic AI scorecard. It should not act as a decorative dashboard or a single trust score. It should function as a multi-dimensional evidence model that shows whether each dependability layer is ready for production use.
The scorecard should be read as an operational dependability instrument, not as a complete solution to model opacity. For high-risk systems, runtime scorecards and structural explainability should work together.
For AI engineers and developers, the practical challenge is to instrument agentic systems so that reliability, governance, admissibility proof, recovery, traceability, interpretive reliability, and accountability are observable. When those signals are captured, the scorecard can identify weak tool schemas, missing proof gates, slow recovery paths, incomplete traces, weak evidence interpretation, or unclear ownership before autonomy expands.
The future of agentic AI engineering is not only about building more capable agents. It is about building measurable, provable, reconstructable, and interpretable systems of trust around those agents.
The core thesis remains simple: reliability makes the agent useful, but pre-admissibility routing, governed-vs-baseline delta, typed signals, admissibility proof, and interpretable runtime evidence make the enterprise able to trust it.